
How to generate AWR in 12.1?
AWR Snapshots and Reports can be created only at the CDB level.
How to generate AWR in 12.2 and later?
How to generate AWR in 12.1?
AWR Snapshots and Reports can be created only at the CDB level.
How to generate AWR in 12.2 and later?
AWS CLI is an common CLI tool for managing the AWS resources. With this single tool we can manage all the aws resources.
sudo apt-get install -y python-dev python-pip
sudo pip install awscli
aws --version
aws configure
cat # output a file
tee # split output into a file
cut -f 2 # print the 2nd column, per line
sed -n ‘5{p;q}’ # print the 5th line in a file
sed 1d # print all lines, except the first
tail -n +2 # print all lines, starting on the 2nd
head -n 5 # print the first 5 lines
tail -n 5 # print the last 5 lines
expand # convert tabs to 4 spaces
unexpand -a # convert 4 spaces to tabs
wc # word count
tr ‘ ‘ \t # translate / convert characters to other characters
sort # sort data
uniq # show only unique entries
paste # combine rows of text, by line
join # combine rows of text, by initial column value
list all trails
aws cloudtrail describe-trails
list all S3 buckets
aws s3 ls
create a new trail
aws cloudtrail create-subscription \
--name awslog \
--s3-new-bucket awslog2016
list the names of all trails
aws cloudtrail describe-trails --output text | cut -f 8
get the status of a trail
aws cloudtrail get-trail-status \
--name awslog
delete a trail
aws cloudtrail delete-trail \
--name awslog
delete the S3 bucket of a trail
aws s3 rb s3://awslog2016 --force
add tags to a trail, up to 10 tags
aws cloudtrail add-tags \
--resource-id awslog \
--tags-list "Key=log-type,Value=all"
list the tags of a trail
aws cloudtrail list-tags \
--resource-id-list
remove a tag from a trail
aws cloudtrail remove-tags \
--resource-id awslog \
--tags-list "Key=log-type,Value=all"
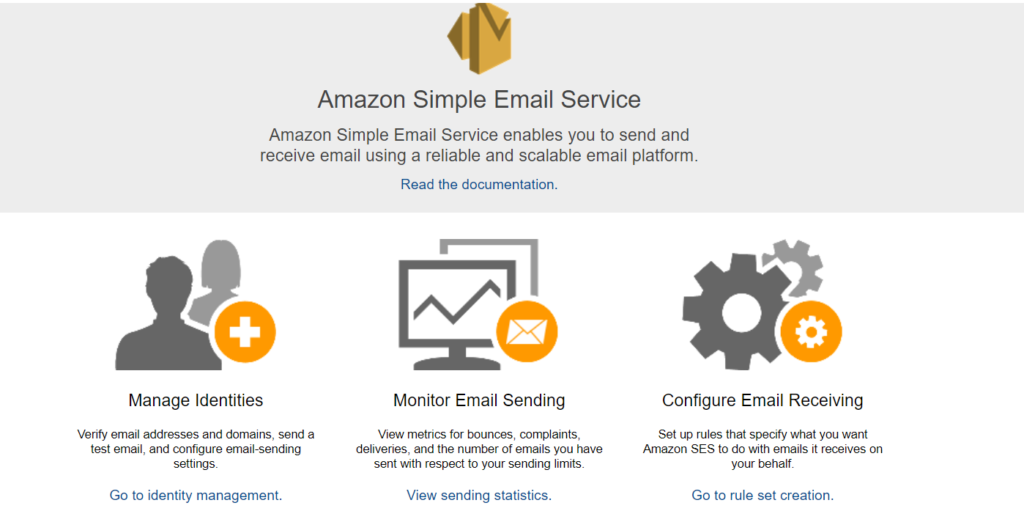
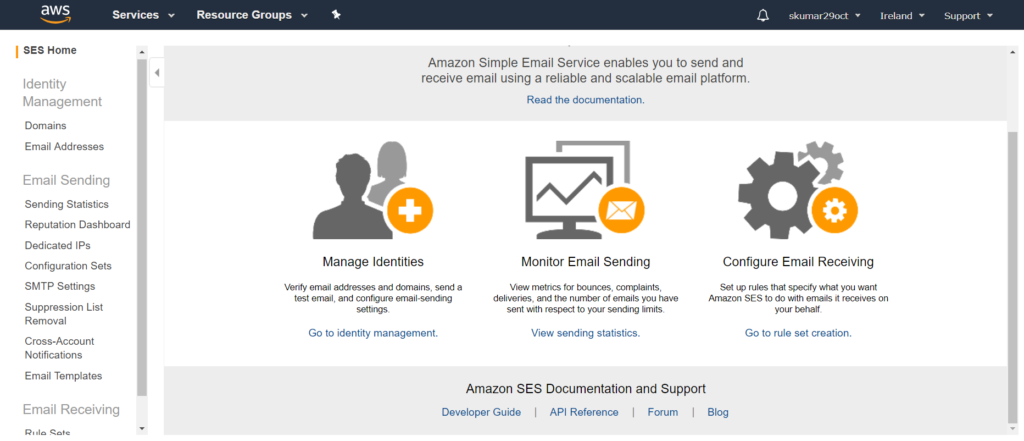
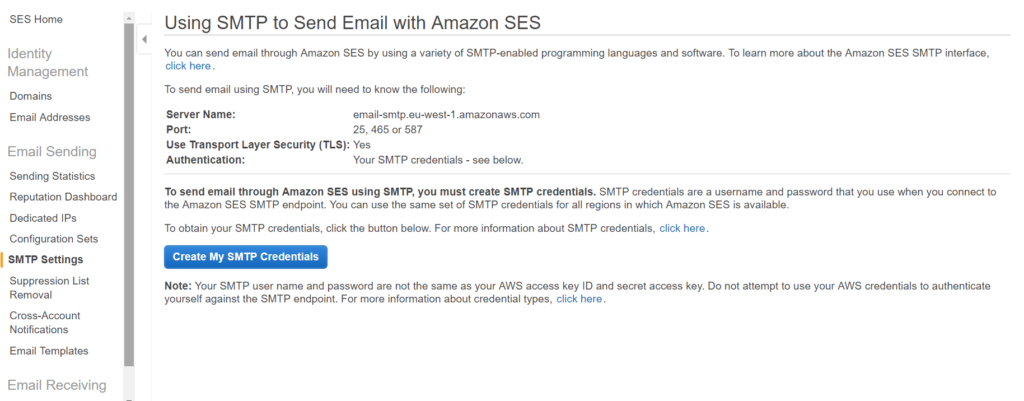
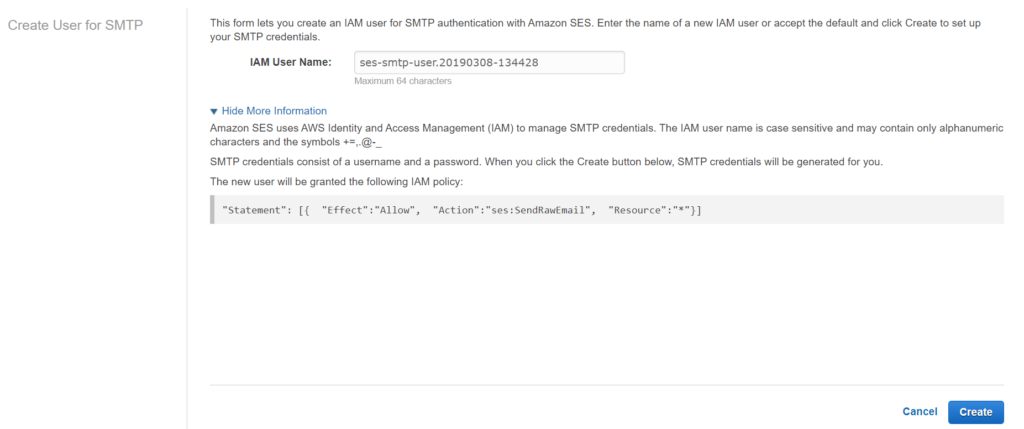
In this article we will see how to use the SES.
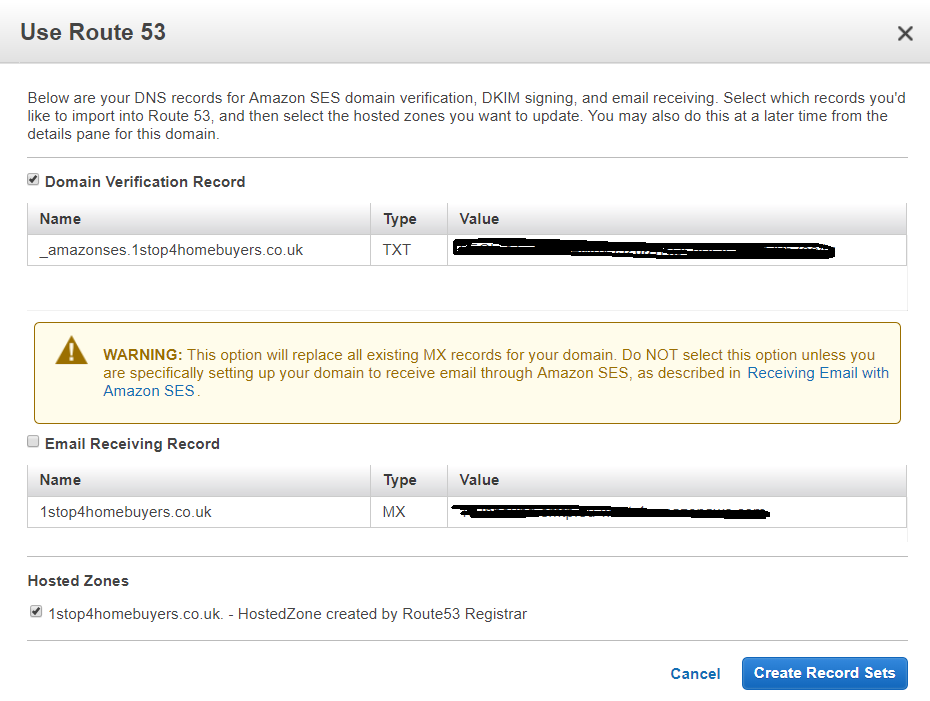
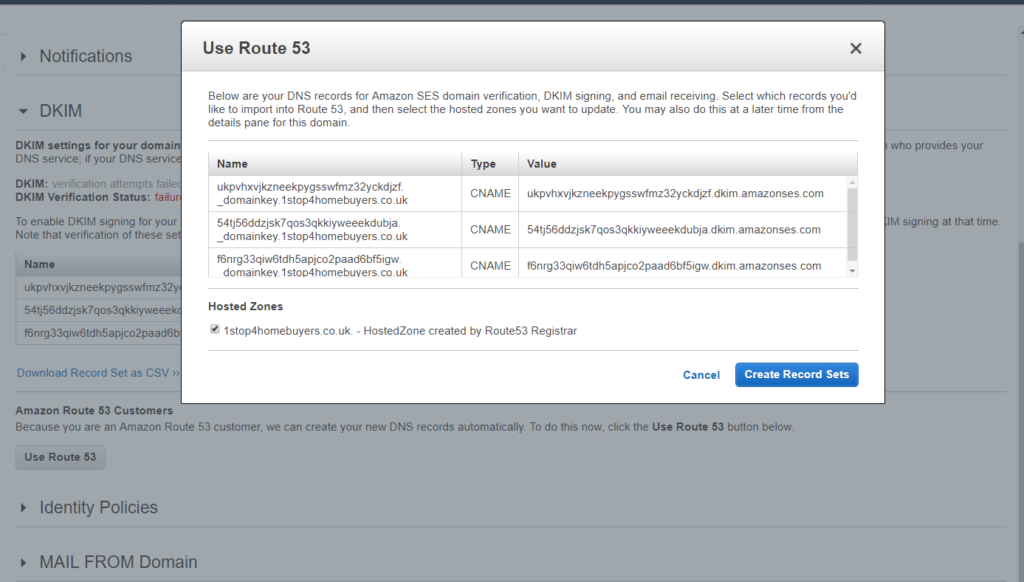
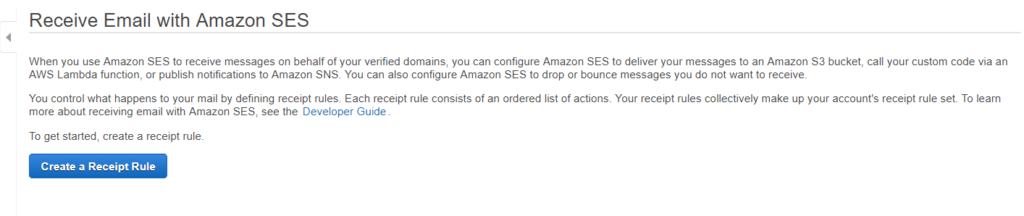
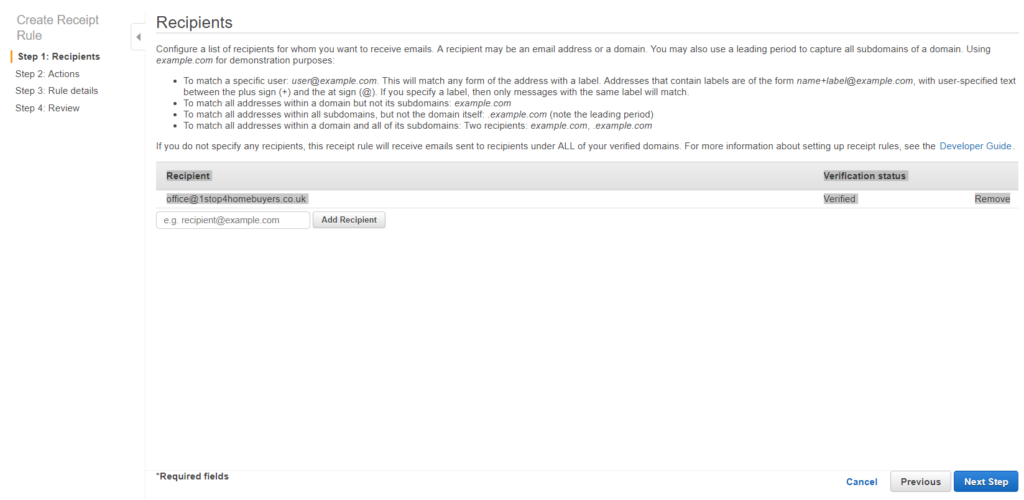
Once logged in aws console click the ‘Simple Email Service’ under the ‘Customer Engagement’. You will see below option.


S3 (Simple Storage Service)
How to access the S3?
Go to “Services” ==> S3, please see the below screenshot for more details.
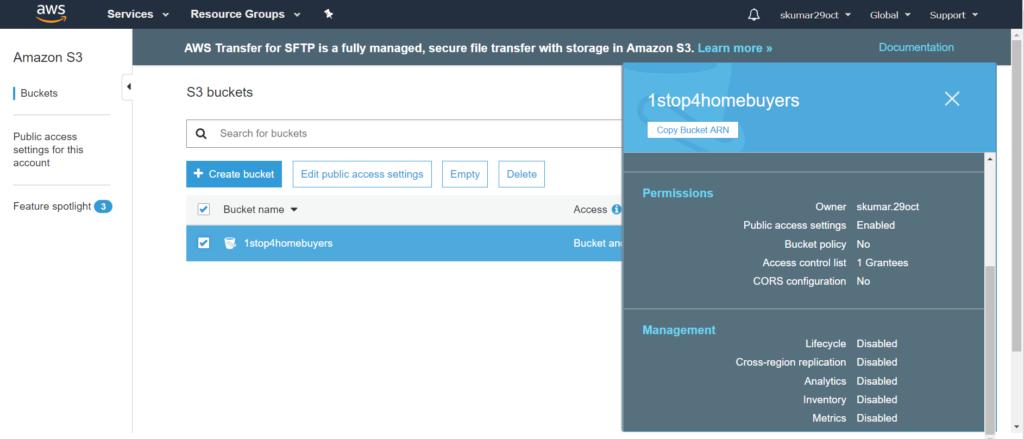
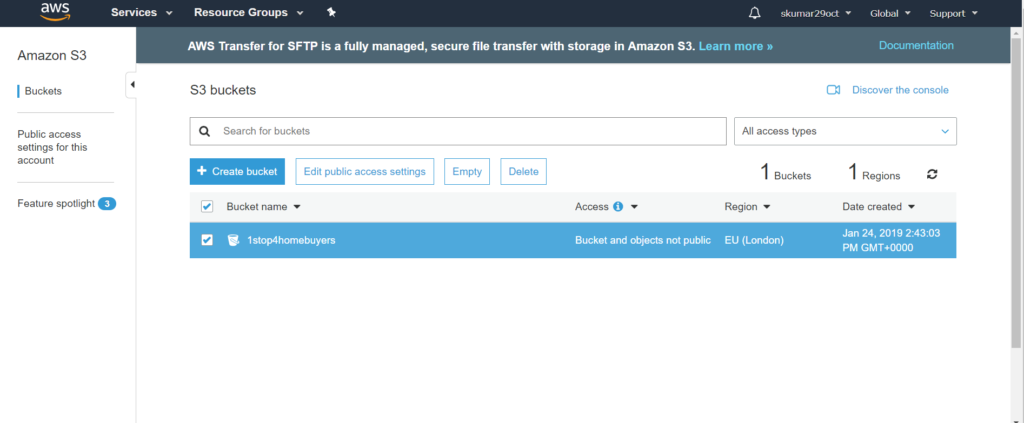

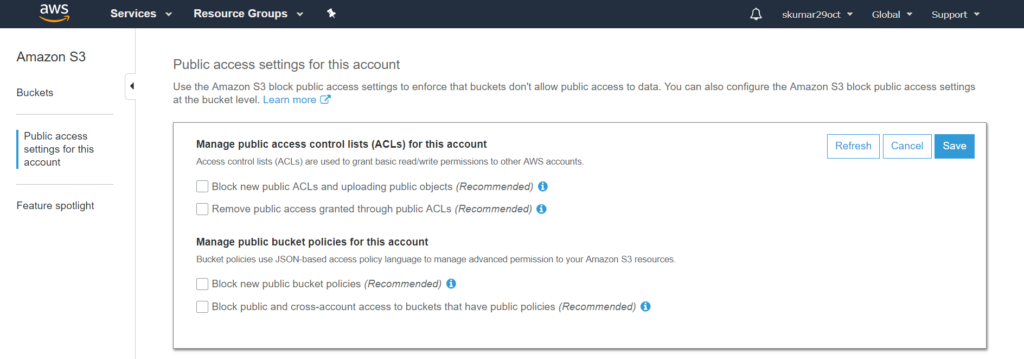
S3 Glacier is a really low cost storage service that provide secure, durable and flexible storage for backup and archival data.
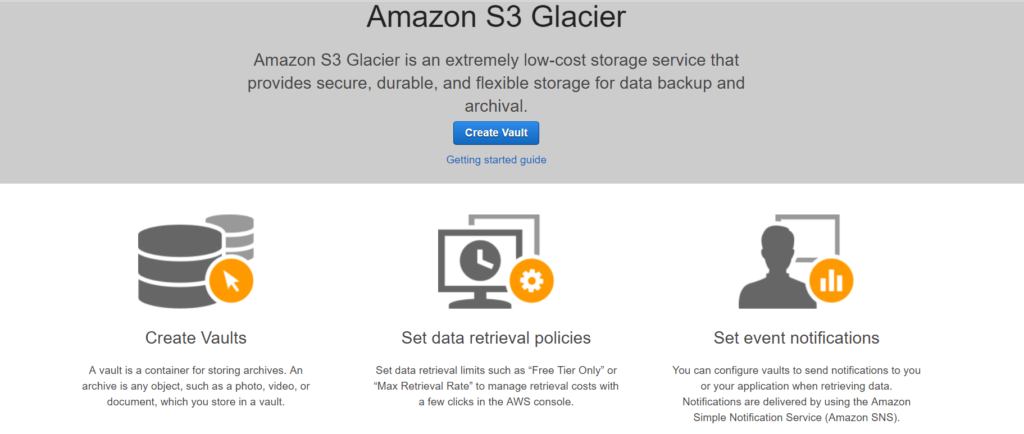
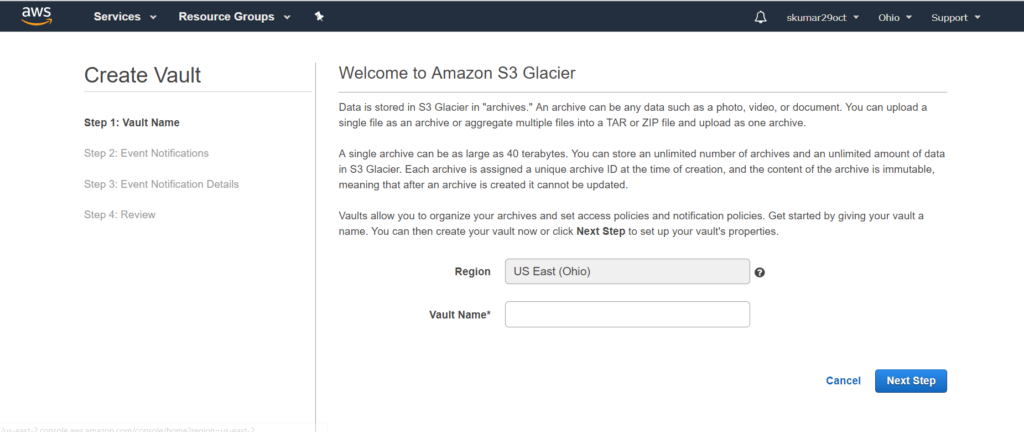
Note: Don’t confuse EC2 with S3.
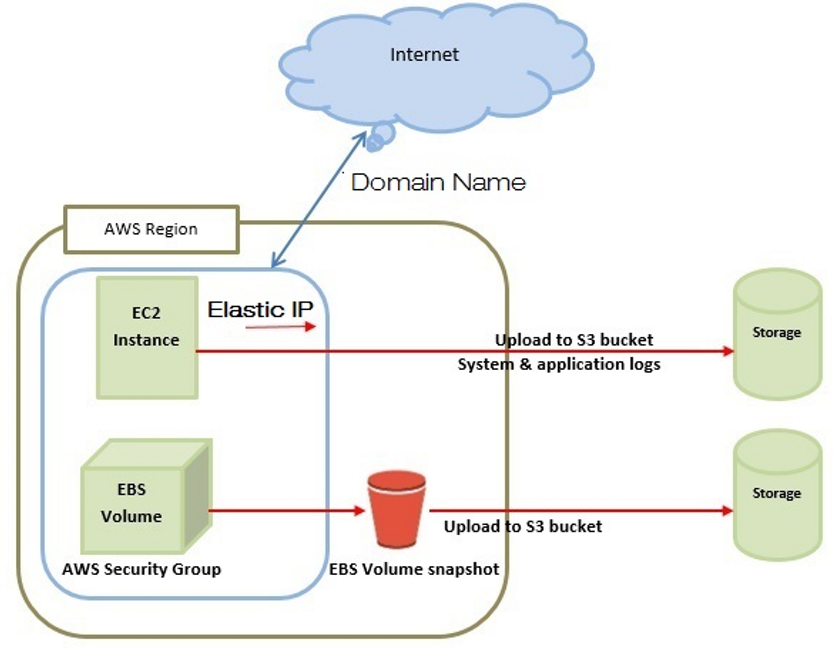
Because S3 is a repository for Internet data which provides access to reliable, fast, and inexpensive data storage infrastructure. S3 is designed to make web-scale computing easy by enabling you to store and retrieve any amount of data, at any time, from within Amazon EC2 OR anywhere on the web.
EC2 Instance:(Elastic Compute Cloud)
EBS: (Elastic Block Storage) (EBS store data using buckets)
S3 (Simple Storage Service)
A: EC2 is an Infrastructure as a Service Cloud Computing Platform provided by Amazon Web Services, that allows users to instantiate various types of virtual machines.
A: An EC2 instance is a Virtual Machine running on Amazon’s EC2 Cloud.
A: An AMI (Amazon Machine Image) is a preconfigured bootable machine image, that allows one to instantiate an EC2 instance. (EC2 Virtual Machine)
A: An AKI (Amazon Kernel Image) is a preconfigured bootable kernel miniimage, that are prebuild and provided by Amazon to boot instances. Typically one will use an AKI that contains pv-grub so that one can instantiate an instance from an AMI that contains it’s own Xen DomU kernel that is managed by the user.
Answer:
A: Please note this difference is only applicable to EBS-root instances.
A: Modern EC2 instances typically exist in a “VPC”, or Virtual Private Cloud network. A VPC is a network overlay environment allowing the user to specify various aspects of the network topology including CIDR ranges, subnets, routing tables, and ACLs. Instances are assigned one or more network interfaces in a VPC, each of which can have one or more IP addresses. Publicly routable IPv6 addresses are available. IPv4 addressing is handled using private RFC 1918 addresses and stateless 1:1 NAT for public internet access.
A legacy “classic” networking mode exists in which each instance is given a randomly assigned private IP address that maps via NAT to an also randomly assigned public IP address. Amazon is not provisioning this feature for new accounts. VPC instances allow more control of the private (and public) IP address mappings and assignment, and as such let one assign custom private IP ranges and addresses, in addition to having the option to not assign public IP address mappings.
A: An Elastic IP address is a Public IP addressed that is assigned to an individual AWS account. These IPs are assigned by region. This address can be assigned to any EC2 instance within a region and will replace the regularly assigned random public IP address.
A: An EC2 Region refers to a geographic region that is a completely autonomous set of compute resources, with their own management infrastructure. Regions do not share any resources, so they are considered completely separate for disaster recovery purposes.
A: The official list of regions grows with some regularity. In general, the latest Debian AMIs are available in all public regions. There is also the non-public GovCloud region, available only to US Government agencies. At present, Debian AMIs are not published in GovCloud, but users have requested them.
A: An availability zone is a separate “failure zone” within a given region that can have resources instantiated in. Each region has it’s own power grid, and physical set of hardware and resources. Availability zones within a given region have a shared management interface/infrastructure.
A: A Security Group (SG) is a management construct within EC2 that acts similarily to a network based firewall. An instance must be assigned one or more security groups at first instantiation. Security group membership may not change after initial instantiation. Security groups allow one to set incoming network rules allowing certain TCP/UDP/ICMP protocols ingress via rules based on incoming security group ID, network address or IP address. Security groups do not restrict outbound traffic, nor do they restrict traffic between instances within the same security group. (Assuming they are communicating via their private IP addresses.)
A: Instance metadata is descriptive information about a particular instance, that is available via an http call to a particular instance and that instance alone. e.g. – Public IP address, availability zone, etc. userdata is one of these pieces of data available.
A: When one instantiates an EC2 instances one may optionally pass 16 KB of data to the API that can be used by the instance. (Typically use cases are running scripts, and/or configuring the instance to meet a particular use case.)
A: Cloud-init is a framework written in Python for handling EC2 userdata to configure a newly instantiated EC2 instance. See upstream project for more details: https://help.ubuntu.com/community/CloudInit
A: When you instantiate an instance from an official Debian AMI, one needs to assign a previously uploaded/created ssh public key, which will be added to the “admin” user’s authorized_keys. One can then ssh in as “admin” and use sudo to add additional users.
A: Either via the AWS Web Console, via the API, or via CLI tools.
A: https://console.aws.amazon.com/
A: http://docs.amazonwebservices.com/AWSEC2/latest/APIReference/Welcome.html
A: The AWS Command Line Interface, available under the DFSG-compliant Apache 2 license, can be installed via apt install awscli on Jessie systems and above. Historical note: the original Amazon EC2 API Tools were not DFSG-compliant, but Debian (still) distributes alternate set of DFSG-compliant tools, that are designed to be fully compatible, called euca2ools.
A: The following page has a list of Official and unofficial Debian AMIs: Cloud/AmazonEC2Image. See also 694035 for work in progress on a machine-readable list.
A: Stretch (and later) AMIs are created using the FAI tool using the debian-cloud-images configuration. An introduction into creating customized AMIs based on the FAI configuration can be found on Noah’s blog.
Packer is another popular tool for creating AMIs. It has the ability to integrate with existing configuration management systems such as chef and puppet, and be used to create images based on customizations performed on a running instance.
Anders Ingemann has created a build script for bootstrapping instances, and was used to create the official AMIs for jessie and earlier. The script can be automated as it needs no user interaction. Custom scripts can be attached to the process as well. You can download or clone the script from github. Any bugs or suggestions should be reported via the github issue tracker. The script is packaged and will be available for install starting with Debian Wheezy.
Also refer to Amazon’s documentation on this topic.
Note: Don’t confuse EC2 with S3 because S3 is
is a repository for Internet data which provides access to reliable, fast, and inexpensive data storage infrastructure. S3 is designed to make web-scale computing easy by enabling you to store and retrieve any amount of data, at any time, from within Amazon EC2 OR anywhere on the web.
Login and click on ==> Resources
Login and click on ‘Resouce Groups’
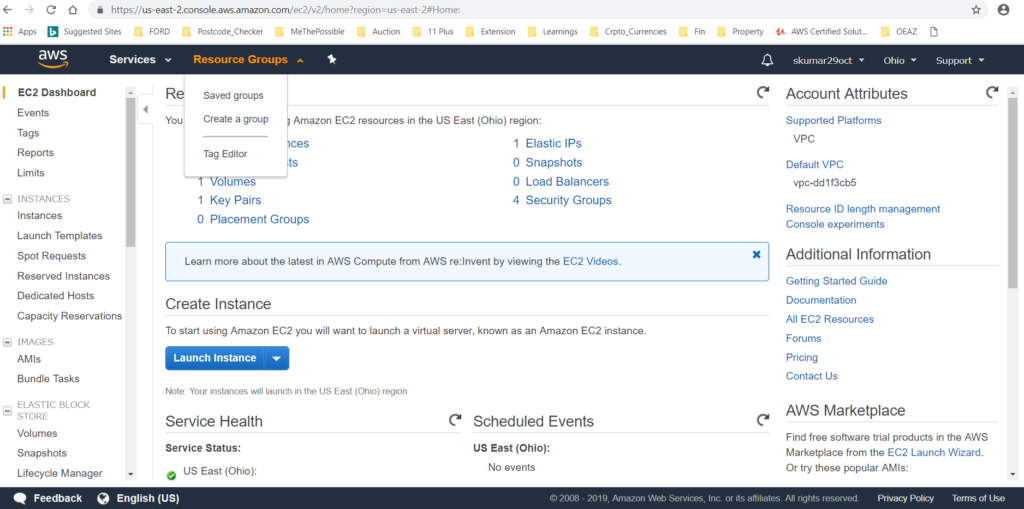
Resources ==> EC2 (Under the Compute).
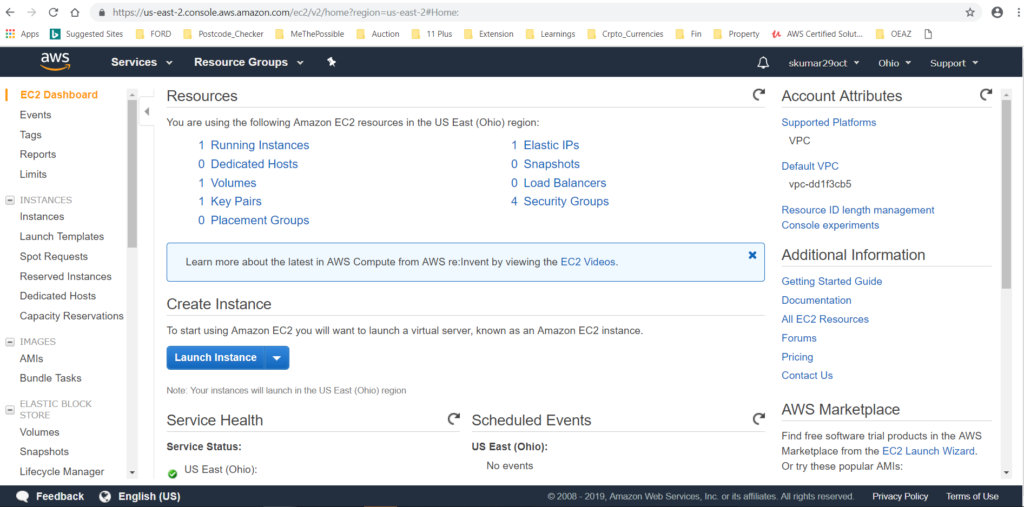
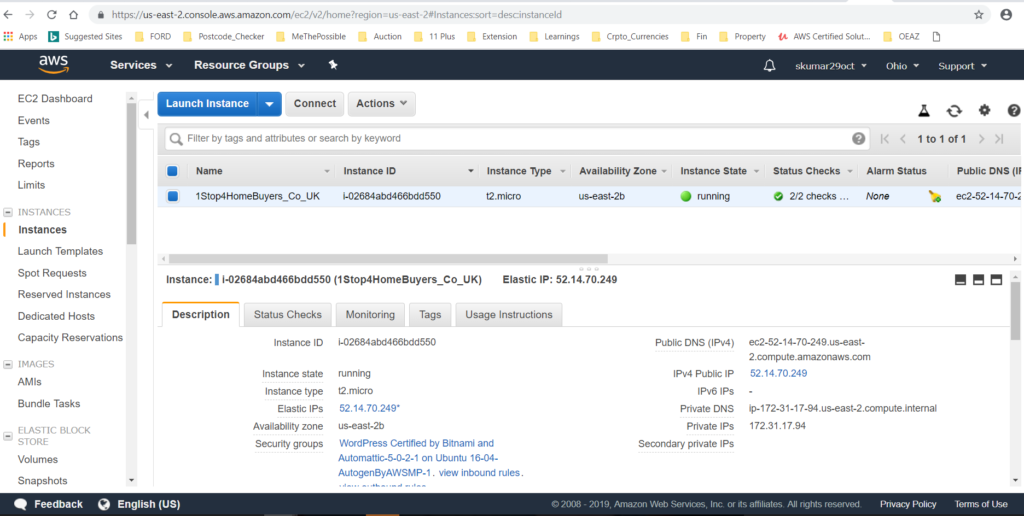
Services ==> EC2 ==> Running Instances
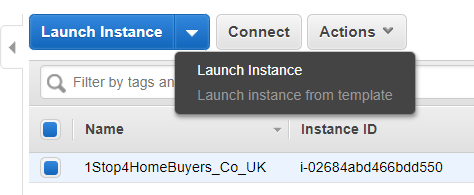
2. Here are the different options under the ‘Actions’
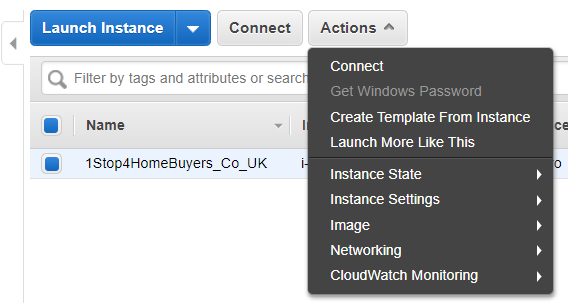
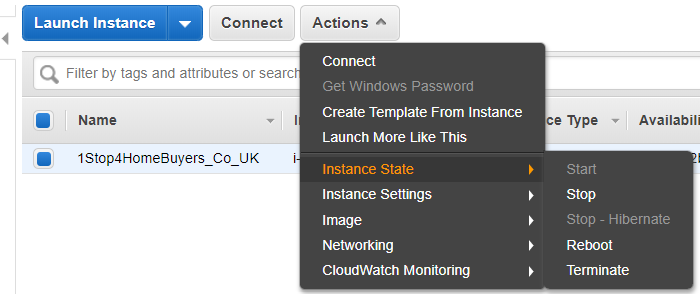
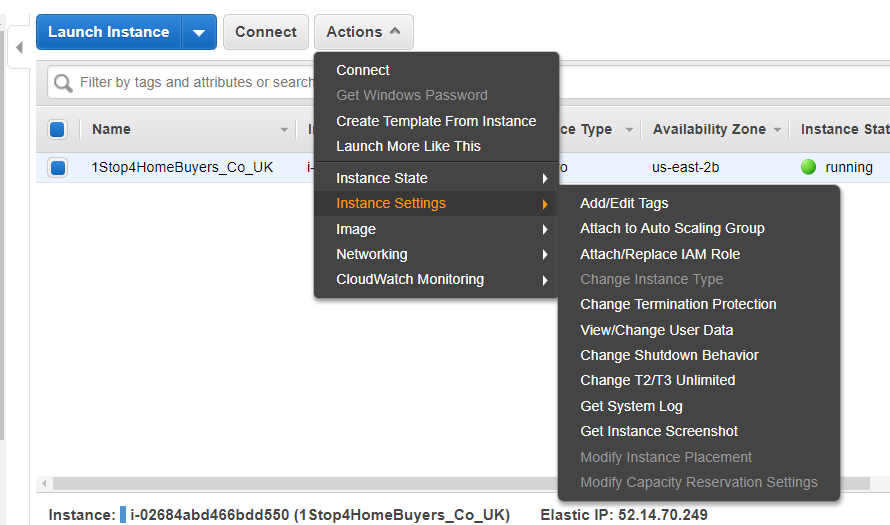
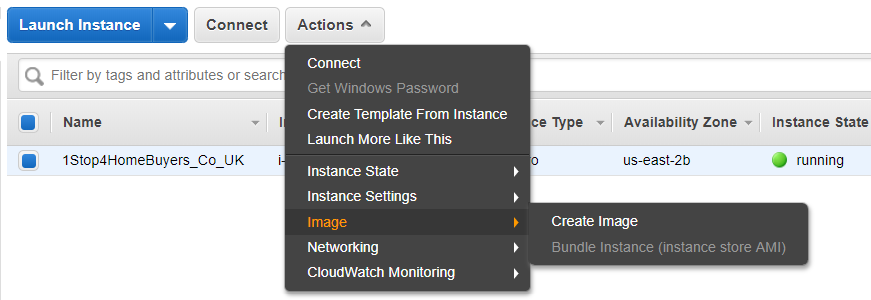
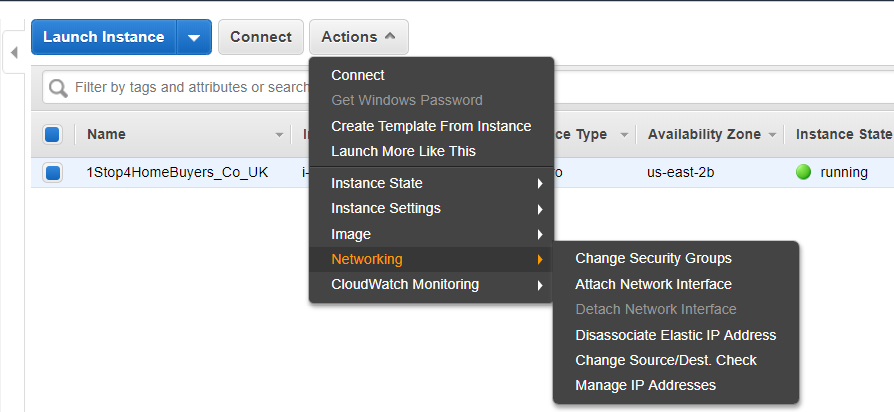
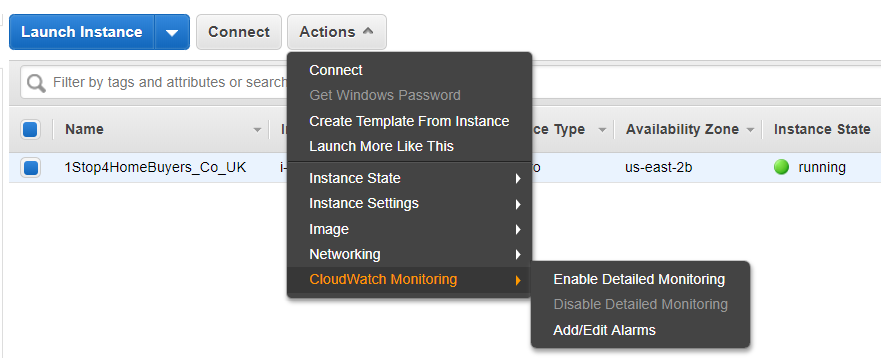
Here you can check the ‘Description’, ‘Status Check’, ‘Monitoring’ ,’Tag’, and Usage Instructions’.
FAQs on Amazon Elastic Compute Cloud (EC2).
t
1. Start the database-based repository i.e. start the database.
set the correct ORACLE_HOME and ORACLE_SID
Start the Net Listener:$ORACLE_HOME/bin/lsnrctl start
Start the database instance:
$ORACLE_HOME/bin/sqlplus
SQL> connect SYS as SYSDBA
SQL> startup
2. Start the Oracle WebLogic Server Administration Server.
You can start/stop WebLogic Server Administration Servers using the WLST command line or a script.$DOMAIN_HOME/bin/startWebLogic.sh <
Note: While you start/stop also start/stop the processes running in the Administration Server including the WebLogic Server Administration Console and Fusion Middleware Control.
3. Ensure Node Manager is running. Below is the script to stat it.$WLS_HOME/server/bin/startNodeManager.sh
OR$DOMAIN_HOME/bin/startNodeManager.sh
Note: stopNodeManager.sh can be used to stop it.
4. Start Oracle Identity Management system components.
Set $ORACLE_HOME and $ORACLE_INSTANCE environment for Identity Management components.
Start/stop OPMN and all system components:$ORACLE_INSTANCE/bin/opmnctl startall
Steps, in order, to stop Fusion Middleware environment
1. Stop system components as Oracle HTTP Server etc.
Note: You can stop them in any order.
Set $ORACLE_HOME and $ORACLE_INSTANCE$ORACLE_INSTANCE/bin/opmnctl stopall
To stop Oracle Management Agent, use the following command:
opmnctl stopproc ias-component=EMAGENT
2. Stop WebLogic Server Managed Servers.
Note: Any applications deployed to the server are also stopped.$DOMAIN_HOME/bin/startManagedWebLogic.sh
managed_server_name admin_url
3. Stop Oracle Identity Management components.
set $ORACLE_HOME environment variable to the Oracle home for the Identity Management components.$ORACLE_INSTANCE/bin/opmnctl stopall
4.Stop the Administration Server.
You can start Server Administration Servers using the WLST command line or a script.
$DOMAIN_HOME/bin/bin/stopWebLogic.sh
Note: While you start/stop also start/stop the processes running in the Administration Server including the WebLogic Server Administration Console and Fusion Middleware Control.
5. Stop the database.
Set $ORACLE_HOME and $ORACLE_INSTANCEconnect SYS as SYSDBA
SQL> shutdown immediate ;
SET ECHO off
SET FEEDBACK 8
SET HEADING ON
SET LINESIZE 230
SET PAGESIZE 300
SET TERMOUT ON
SET TIMING OFF
SET TRIMOUT ON
SET TRIMSPOOL ON
SET VERIFY OFF
CLEAR COLUMNS
CLEAR BREAKS
CLEAR COMPUTES
COLUMN disk_group_name FORMAT a20 HEAD ‘Disk Group Name’
COLUMN disk_path FORMAT a20 HEAD ‘Disk Path’
COLUMN reads FORMAT 999,999,999,999 HEAD ‘Reads’
COLUMN writes FORMAT 999,999,999,999 HEAD ‘Writes’
COLUMN read_errs FORMAT 999,999,999 HEAD ‘Read|Errors’
COLUMN write_errs FORMAT 999,999,999 HEAD ‘Write|Errors’
COLUMN read_time FORMAT 999,999,999,999 HEAD ‘Read|Time’
COLUMN write_time FORMAT 999,999,999,999 HEAD ‘Write|Time’
COLUMN bytes_read FORMAT 999,999,999,999,999 HEAD ‘Bytes|Read’
COLUMN bytes_written FORMAT 999,999,999,999,999 HEAD ‘Bytes|Written’
BREAK ON report ON disk_group_name SKIP 2
COMPUTE sum LABEL “” OF reads writes read_errs write_errs read_time write_time bytes_read bytes_written ON disk_group_name
COMPUTE sum LABEL “Grand Total: ” OF reads writes read_errs write_errs read_time write_time bytes_read bytes_written ON report
SELECT
a.name disk_group_name
, b.path disk_path
, b.reads reads
, b.writes writes
, b.read_errs read_errs
, b.write_errs write_errs
, b.read_time read_time
, b.write_time write_time
, b.bytes_read bytes_read
, b.bytes_written bytes_written
FROM v$asm_diskgroup a JOIN v$asm_disk b USING (group_number)
ORDER BY a.name ;