
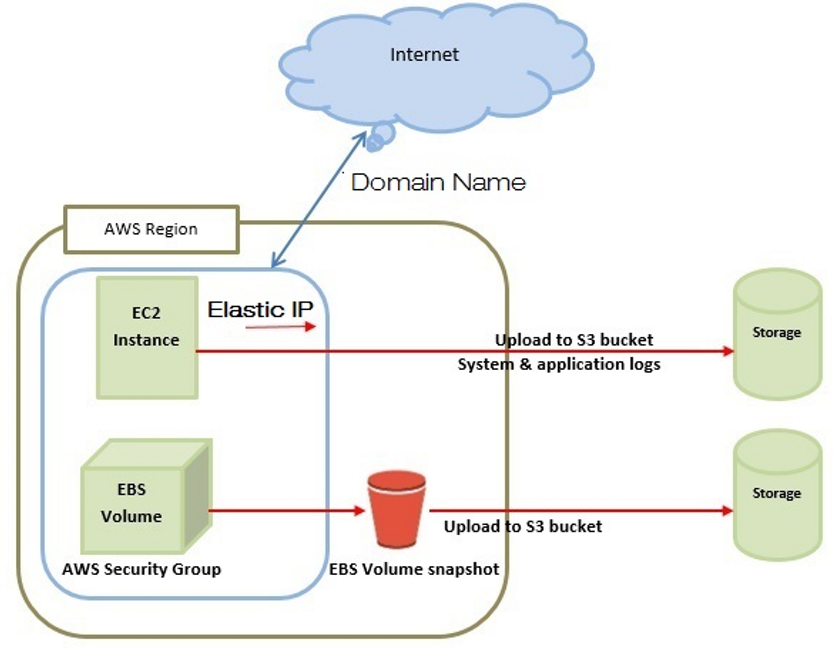
Note: Don’t confuse EC2 with S3.
Because S3 is a repository for Internet data which provides access to reliable, fast, and inexpensive data storage infrastructure. S3 is designed to make web-scale computing easy by enabling you to store and retrieve any amount of data, at any time, from within Amazon EC2 OR anywhere on the web.
EC2 Instance:(Elastic Compute Cloud)
- Elastic Compute Cloud EC2 instance is like a remote computer running Windows or Linux and on which you can install whatever software you want, including a Web server running PHP code and a database server.
- EC2 is an Infrastructure as a Service (IaaS) Cloud Computing Platform provided by Amazon Web Services, that allows users to instantiate various types of virtual machines.
- EC2 provides scalable computing capacity in the Amazon Web Services (AWS) cloud. Using Amazon EC2 eliminates your need to invest in hardware up front, so you can develop and deploy applications faster.
- EC2 FAQs
- More details about EC2
EBS: (Elastic Block Storage) (EBS store data using buckets)
- EBS stands for Elastic Block Storage, and is a service that provides dynamically allocatable, persistent, block storage volumes that can be attached to EC2 instances.
- Most system operations that can be performed with an HDD can be performed with an EBS volume. e.g. – formatted with a filesystem and mounted.
- EBS also provides additional SAN-like features such as taking snapshots of volumes, and detaching and reattaching volumes dynamically.
- One notable feature that SAN LUNs support that EBS volumes do not is muti-initiator. (IE: Only a single EC2instance can be associated with a given EBS volume at a given time, so shared storage clustering is currently not supported.).
- EBS FAQs
- More about EBS
S3 (Simple Storage Service)
- Amazon S3 has a simple web services interface that you can use to store and retrieve any amount of data, at any time, from anywhere on the web.
- It gives any developer access to the same highly scalable, reliable, fast, inexpensive data storage infrastructure that Amazon uses to run its own global network of web sites.
- How to use an S3 bucket? a. First creates a bucket in the AWS region of his or her choice and gives it a globally unique name. AWS recommends that customers choose regions geographically close to them to reduce latency and costs. b. Once the bucket has been created, the user then selects a tier for the data. c. Bucket name are unique across aws.
- An AWS customer can interact with an Amazon S3 bucket using any of 3 methods. a. AWS Management Console. b.AWS Command Line Interface. c. application programming interfaces (APIs).
- S3 FAQs
- Really good article about “What S3 is not”?
- More about S3 and buckets
- NOTES: There are three tiers of S3 Storage available: S3 Standard – Durable, immediately available suitable for frequently accessed data. By default, data stored in S3 is written across multiple devices in multiple locations providing resiliency. (SLA: 99.99% availability & 99.99999999999% durability). S3 IA (Infrequently Accessed) – This is the same service as S3 although available at a lower cost. S3 IA users pay a retrieval fee meaning it is only a cost effective storage option for data that isn’t frequently accessed. Reduced Redundancy Storage – A lower cost storage solution with reduced SLAs (SLA: 99.99% availability & durability). c. Then, the user can specify access privileges for the objects stored in a bucket, through mechanisms such as the AWS Identity and Access Management service, bucket policies and access control lists.