1. How to Determine Which Manager Ran a Specific Concurrent Request?
col USER_CONCURRENT_QUEUE_NAME for a100 select b.USER_CONCURRENT_QUEUE_NAME from fnd_concurrent_processes a, fnd_concurrent_queues_vl b, fnd_concurrent_requests c where a.CONCURRENT_QUEUE_ID = b.CONCURRENT_QUEUE_ID and a.CONCURRENT_PROCESS_ID = c.controlling_manager and c.request_id = ‘&conc_reqid’;
2. Concurrent manager status for a given sid?
col MODULE for a20 col OSUSER for a10 col USERNAME for a10 set num 10 col MACHINE for a20 set lines 200 col SCHEMANAME for a10 select s.sid,s.serial#,p.spid os_pid,s.status, s.osuser,s.username, s.MACHINE,s.MODULE, s.SCHEMANAME, s.action from gv$session s, gv$process p WHERE s.paddr = p.addr and s.sid = ‘&oracle_sid’;
3. Find out request-id from Oracle_Process Id:
select REQUEST_ID,ORACLE_PROCESS_ID,OS_PROCESS_Id from apps.fnd_concurrent_requests where ORACLE_PROCESS_ID=’&a’;
4. To find sid,serial# for a given concurrent request id?
set lines 200 SELECT a.request_id, d.sid, d.serial# ,d.osuser,d.process , c.SPID ,d.inst_id FROM apps.fnd_concurrent_requests a, apps.fnd_concurrent_processes b, gv$process c, gv$session d WHERE a.controlling_manager = b.concurrent_process_id AND c.pid = b.oracle_process_id AND b.session_id=d.audsid AND a.request_id = &Request_ID AND a.phase_code = ‘R’;
5. To find concurrent program name, phase code, and status code for a given request id?
6. To find the SQL query for a given concurrent request sid?
select sid,sql_text from gv$session ses, gv$sqlarea sql where ses.sql_hash_value = sql.hash_value(+) and ses.sql_address = sql.address(+) and ses.sid=’&oracle_sid’ /
7. To find child requests
set lines 200 col USER_CONCURRENT_PROGRAM_NAME for a40 col PHASE_CODE for a10 col STATUS_CODE for a10 col COMPLETION_TEXT for a20 SELECT sum.request_id,req.PARENT_REQUEST_ID,sum.user_concurrent_program_name, DECODE (sum.phase_code,’C’,’Completed’,sum.phase_code) phase_code, DECODE(sum.status_code,’D’, ‘Cancelled’ , ‘E’, ‘Error’ , ‘G’, ‘Warning’, ‘H’,’On Hold’ , ‘T’, ‘Terminating’, ‘M’, ‘No Manager’ , ‘X’, ‘Terminated’, ‘C’, ‘Normal’, sum.status_code) status_code, sum.actual_start_date, sum.actual_completion_date, sum.completion_text FROM apps.fnd_conc_req_summary_v sum, apps.fnd_concurrent_requests req where req.request_id=sum.request_id and req.PARENT_REQUEST_ID = ‘&parent_concurrent_request_id’;
8. Cancelling Concurrent request :
update fnd_concurrent_requests set status_code=’D’, phase_code=’C’ where request_id=&req_id;
9. Kill sessions program wise
select ‘ALTER SYSTEM KILL SESSION ”’||sid||’,’||serial#||”’ immediate;’ from v$session where MODULE like ”;
10 . Concurrent Request running by SID
SELECT a.request_id, d.sid as Oracle_SID, d.serial#, d.osuser, d.process, c.SPID as OS_Process_ID FROM apps.fnd_concurrent_requests a, apps.fnd_concurrent_processes b, gv$process c, gv$session d WHERE a.controlling_manager = b.concurrent_process_id AND c.pid = b.oracle_process_id AND b.session_id=d.audsid AND d.sid = &SID; 11. Find out request-id from Oracle_Process Id:
select REQUEST_ID,ORACLE_PROCESS_ID,OS_PROCESS_Id from fnd_concurrent_requests where ORACLE_PROCESS_ID=’&a’;
12. Oracle Concurrent Request Error Script (requests which were errored out)
SELECT a.request_id “Req Id” ,a.phase_code,a.status_code , actual_start_date , actual_completion_date ,c.concurrent_program_name || ‘: ‘ || ctl.user_concurrent_program_name “program” FROM APPLSYS.fnd_Concurrent_requests a,APPLSYS.fnd_concurrent_processes b ,applsys.fnd_concurrent_queues q ,APPLSYS.fnd_concurrent_programs c ,APPLSYS.fnd_concurrent_programs_tl ctl WHERE a.controlling_manager = b.concurrent_process_id AND a.concurrent_program_id = c.concurrent_program_id AND a.program_application_id = c.application_id AND a.status_code = ‘E’ AND a.phase_code = ‘C’ AND actual_start_date > sysdate – 2 AND b.queue_application_id = q.application_id AND b.concurrent_queue_id = q.concurrent_queue_id AND ctl.concurrent_program_id = c.concurrent_program_id AND ctl.LANGUAGE = ‘US’ ORDER BY 5 DESC;
13. Request submitted by User
SELECT user_concurrent_program_name, request_date, request_id, phase_code, status_code FROM fnd_concurrent_requests fcr, fnd_concurrent_programs_tl fcp, fnd_responsibility_tl fr, fnd_user fu WHERE fcr.CONCURRENT_PROGRAM_ID = fcp.concurrent_program_id and fcr.responsibility_id = fr.responsibility_id and fcr.requested_by = fu.user_id and user_name = ‘&user’ AND actual_start_date > sysdate – 1 ORDER BY REQUEST_DATE Asc;
14. Concurrent Program enables trace
col User_Program_Name for a40 col Last_Updated_By for a30 col DESCRIPTION for a30 SELECT A.CONCURRENT_PROGRAM_NAME “Program_Name”, SUBSTR(A.USER_CONCURRENT_PROGRAM_NAME,1,40) “User_Program_Name”, SUBSTR(B.USER_NAME,1,15) “Last_Updated_By”, SUBSTR(B.DESCRIPTION,1,25) DESCRIPTION FROM APPS.FND_CONCURRENT_PROGRAMS_VL A, APPLSYS.FND_USER B WHERE A.ENABLE_TRACE=’Y’ AND A.LAST_UPDATED_BY=B.USER_ID;
In R12.2 we have 2 file systems RUN and PATCH. Whenever we are making any changes in context file always make those in both RUN and PATCH context file to keep them in sync.
Below are the steps to execute autoconfig in R12.2 Environments In below example I am making changes to forms trace directory.
Make sure: 1.Make sure your application services are down. 2.Database services and Listener should be up and running. 3.Identify the Context which needs to be modified. 4.In R12.2 make sure you run Autoconfig on both run and patch file. 5.Getting context file use below
Source Run File system . EBSapps.env run echo $CONTEXT_FILE ( This will give you full path with Context file name in run file system)
Source Patch File System . EBSapps.env patch echo $CONTEXT_FILE ( This will give you full path with Context file name in patch file system)
NOTE: Make the necessary parameter changes in Both the context files. But always ensure to take a copy of the respective context files(Run and Patch) before changing.
Connect to putty as applmgr. Stop AP Tier $ sh <ADMIN_SCRIPTS_HOME>/adstpall.sh apps/<pwd>
Run autoconfig Source RUN file system cd $ADMIN_SCRIPTS_HOME ./adautocfg.sh
Make sure it completes successfully.
Now make sure, required changes have taken place and start the service.
Start AP Tier $ sh <ADMIN_SCRIPTS_HOME>/adstrtal.sh apps/<pwd>
=> adpreclone.pl script prepares the source system to be cloned by collecting information about source system by creating a cloning stage area, generate template and drivers from existing files that contain source specific hard coded value.
On Database node
adpreclone.pl dbTier –>
The directories that will be created in $ORACLE_HOME/appsutil/clone are : jlib, db, data
jlib –> Contains the libraries. db –> Database tech stack information. data –> Contains the information related to data files.
It also does the below tasks:
Creates driver files at $ORACLE_HOME/appsutil/driver/instconf.drv. Converts inventory from binary to xml. The XML file is location at $ORACLE_HOME/appsutil/clone/context_name/sid_context.xml Creates database control file script and datafile location information file at $ORACLE_HOME/appsutil/templateadcrdbclone.sql, dbfinfo.lst. Generates database creation driver file at $ORACLE_HOME/appsutil/clone/data/driverdata.drv Copy JDBC Libraries to $ORACLE_HOME/appsutil/clone/jlib.
On Application node
adpreclone.pl appsTier –>
This will create stage directory at $COMMON_TOP/clone. This runs in 2 steps.
Techstack ==> Creates template files for $IAS_ORACLE_HOME/appsutil/template and 806 ORACLE_HOME/appsutil/template. Creates driver files for $IAS_ORACLE_HOME/appsutil/driver/instconf.drv and 806 $ORACLE_HOME/appsutil/driver/instconf.drv.
APPL_TOP ==> It will create application top driver file at $COMMON_TOP/clone/appl/driver/appl.drv. Copy JDBC libraries and $COMMON_TOP/clone/jlib/classes111.zip
It creates a context file. Register ORACLE_HOME Configure ORACLE_HOME Relink ORACLE_HOME Recreate controlfile Configure database Start the database listener.
This will use the templates and driver files those were created while running adpreclone.pl on source system and has been copied to target system.
Following scripts are run by adcfgclone.pl dbTier for configuring techstack
->adchkutl.sh — This will check the system for ld, ar, cc, and make versions. ->adclonectx.pl — This will clone the context file. This will ceate a new context file as per the details of this instance. ->runInstallConfigDriver — located in $ORACLE_HOME/appsutil/driver/instconf.drv -> Relinking $ORACLE_HOME/appsutil/install/adlnkoh.sh — This will relink ORACLE_HOME For data on database side, following scripts are run Driver file $ORACLE_HOME/appsutil/clone/context/data/driver/data.drv Create database adcrdb.zip Autoconfig is run Control file creation adcrdbclone.sql
It is used to configure the database with context file. Database should be in open mode.
On Application Node
perl adcfgclone.pl appsTier
Creates context file for target adclonectx.pl Run driver files $ORACLE_HOME/appsutil/driver/instconf.drv and $IAS_ORACLE_HOME/appsutil/driver/instconf.drv Relinking of Oracle Home $ORACLE_HOME/bin/adlnk806.sh and $IAS_ORACLE_HOME/bin/adlnkiAS.sh Run $COMMON_TOP/clone/appl/driver/appl.drv and then runs autoconfig.
Clone using RMAN (2nd method).
Running Pre-Clone on the Source Apps Tier
cd $ADMIN_SCRIPTS_HOME perl adpreclone.pl appsTier
Running Pre-Clone on the Source DB Tier
cd perl adpreclone.pl dbtier
Copying Application Tier from Source to Target
Copying RDBMS Oracle Home from the Source To Target
connect to target db server with root user and copy databsae oracle home from source to target.
Duplicating/ Opening the cloned database on the Target Database Server
Connect to target , modify your pfile according to your needs, create an spfile and startup nomount your database with the new name on the target server.
Also set your db_file_name_convert, log_file_name_convert parameters before duplicating the db.
db_file_name_convert=(+DATA,/+DATAERMAN)
log_file_name_convert=(+DATA,+DATAERMAN)
SQL>startup nomount;
Connect to the auxilary and duplicate the database with the name by specifying the backup location which resides on your target server.
TARGET>
rman auxiliary /
RMAN>duplicate target database to “PREPROD” BACKUP LOCATION ‘/u01/backup_sil/Bck_For_Clone’;
Running Post Clone in the Target Database Server.
cd <RDBMS ORACLE_HOME>/appsutil/clone/bin
perl adcfgclone.pl dbTier
Copyright (c) 2011 Oracle Corporation
Redwood Shores, California, USA
Oracle E-Business Suite Rapid Clone
Version 12.2
adcfgclone Version 120.63.12020000.7.1202010.2
Enter the APPS password :
Running:
Running Post Clone in the Target Application Tier.
Before executing adcfgclone on AppsTier. Copy the application inventory directory from source to target, and make the necessary modifications in the /etc/oratab file to point to the oraInventory location residing on target server. Also configure the permission -> prevent null pointer exceptions during precheck phase of the post clone.
Note that: You must only have appl_top,common_top and 10.1.2 oracle_home in the target server. If you have copied FMW home ,too; then you will get FMW HOME found error in the beginning of post clone..
cd <COMMON_TOP>/clone/bin
Running Pre-Clone on the Target Apps Tier
perl adcfgclone.pl appsTier
TARGET> login with applmgr
. /u01/EBSapps.env run
cd $ADMIN_SCRIPTS_HOME
sh adadminsrvctl.sh start
Note: weblogic admin server should be up before the execution of preclone script, preclone needs it.
perl adpreclone.pl appsTier
Copying EBSpps directory from Run edition to patch edition (in this case fs2 to fs1) in the Target Application server.
First we create the patch directory , in this case it is fs1
mkdir -p /u01/fs1
Then we copy the run edition’s EBSApps directory keeping the softlinks ;
cp -RH /u01/fs2/EBSapps/ /u01/fs1/
Running postclone on the Patch Edition of the Target Application server & fixing the errors.
unset your env.
cd /u01/fs1/EBSapps/comn/clone/bin (patch edition ‘s clone/bin)
perl adcfgclone.pl appsTier
Starting our clone environment.
. /u01/EBSApps.env run
cd $ADMIN_SCRIPTS_HOME
sh adstrtal.sh apps/apps
That’s it… Our clone environment is up&running. Optionally, we can do other post clone stuff at this point.. I mean, we can change site name and color of the Forms screens, or we can mask our sensitive data etc..
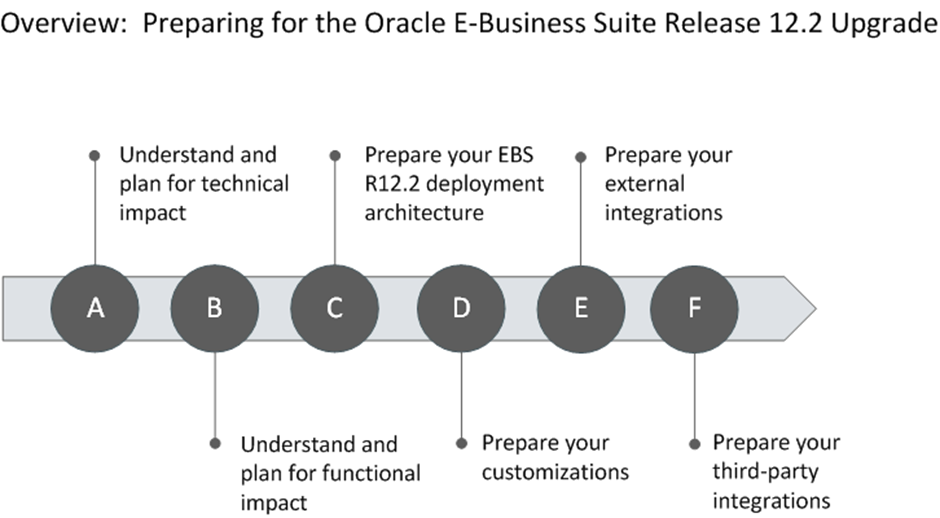
The following diagram describes the high-level overview of the tasks described in this guide:
Overview of the Oracle E-Business Suite Release 12.2 Upgrade Process
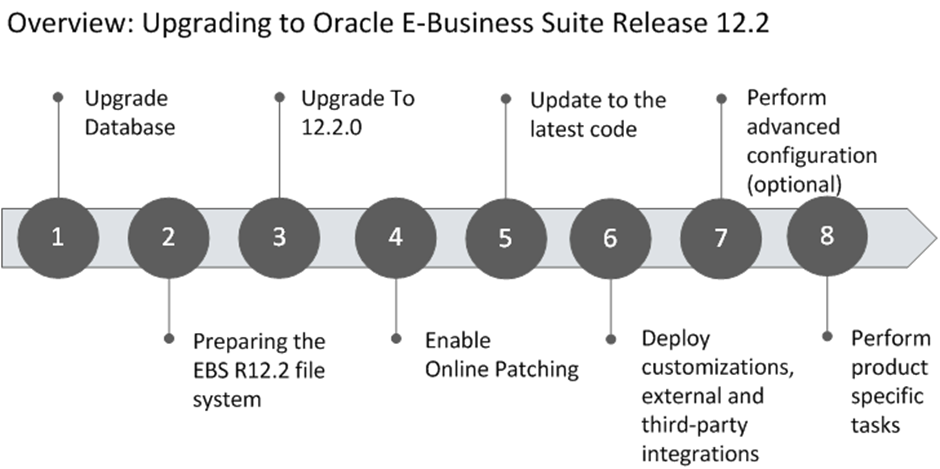
The steps required to upgrade to Oracle E-Business Suite Release 12.2 are documented in the Performing the Upgrade chapter. The upgrade includes a number of steps that can be categorized into the following high-level steps:
The following is a summary of the steps for each category:
Prepare the Database.
Upgrade the database to the minimum version or latest certified version
Migrate to a new platform (optional)
Apply the latest database patches
Lay Down the Oracle E-Business Suite Release 12.2 File System.
Use Rapid Install to lay down the file system and technology stack
Apply the latest application tier technology stack patches
Upgrade to Release 12.2.0.
Apply the latest AD upgrade patch and Oracle E-Business Suite Consolidated Upgrade Patch (CUP)
Apply the latest Oracle E-Business Suite pre-install patches
Apply the 12.2 merged upgrade driver
Run Rapid Install in ‘configure’ mode
Enable Online Patching.
Apply the latest Online Patching Readiness Report Patch
Apply required updates to custom code according to the readiness reports
Apply the enablement patch
Upgrade to the latest code.
Apply the latest AD-TXK RUP
Apply the latest Oracle E-Business Suite Release 12.2 Release Update Pack (RUP)
Note: You must apply the 12.2.3 or later Release Update Pack (RUP) to your existing Release 12.2 system for production use.
RUPs are released periodically. Each one is cumulative and delivers error corrections and system updates, not only for the most current release update pack, but also for all the RUPs that precede it. Oracle highly recommends that when planning your upgrade you plan to upgrade to the latest RUP available.
You can keep current on the latest release information, as well as new RUP announcements and other updates that may affect your upgrade by reviewing the latest version of Oracle Applications Manager Release Notes for Release 12.2.
Complete post-upgrade steps
Apply the latest security patches
Apply all recommended patches
Apply NLS patches (conditional)
Deploy custom code, external integrations and third-party integrations.
Perform advanced configurations.
Scaling up and scaling out, such as adding additional managed servers, adding application tier nodes, or adding Oracle RAC nodes.
Supported in EURC-DT: Yes
Note: The upgrade process is performed with one application tier and one database tier. If you are using an Oracle RAC environment, then you should run the Release 12.2 upgrade on a single Oracle RAC node. The reason for upgrading with a single Oracle RAC node is that most of the elapsed time in the upgrade will be taken by jobs running DML (INSERT, UPDATE, DELETE). These jobs use multiple workers and parallel servers, which typically attempt to access the same objects and blocks concurrently. The consequent additional communication between cluster nodes (and associated cluster waits) significantly outweigh any gains from using the additional CPU’s to increase throughput. Scaling out is a post-upgrade step.
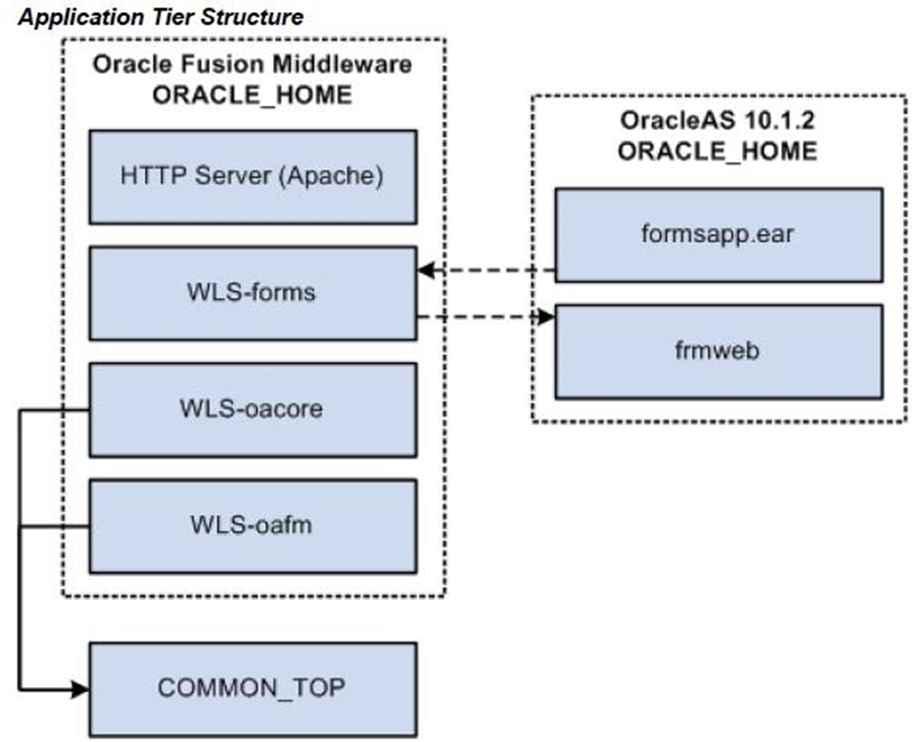
In Release 12.2, Web and Forms services are provided by Oracle Application Server and Oracle Fusion Middleware. They are no longer servers in the sense of being a single process, as was the case in previous releases.
Application Tier ORACLE_HOMEs in Release 12.2
Oracle E-Business Suite Release 12.2 uses two application tier ORACLE_HOMEs.
• An OracleAS 10.1.2 ORACLE_HOME that was used in previous 12.x releases.
• An Oracle Fusion Middleware (FMW) ORACLE_HOME that supports Oracle WebLogic Server (WLS) and supersedes the Java (OracleAS 10.1.3)
ORACLE_HOME that was used in previous releases.
The use of these two ORACLE_HOMEs enable Oracle E-Business Suite to take advantage of the latest Oracle technologies.
Notable features of this architecture include:
• The Oracle E-Business Suite modules (packaged in the file formsapp.ear) are deployed out of the OracleAS 10.1.2 ORACLE_HOME, and the frmweb executable is also invoked out of this ORACLE_HOME.
• All major services are started out of the Fusion Middleware ORACLE_HOME.
Key changes from earlier releases include:
• The Oracle Application Server 10.1.2 ORACLE_HOME (sometimes referred to as the Tools, C, or Developer ORACLE_HOME) replaces the 8.0.6 ORACLE_HOME provided by Oracle9i Application Server 1.0.2.2.2 in Release 11i.
• The FMW ORACLE_HOME (sometimes referred to as the Web or Java ORACLE_HOME) replaces the OracleAS 10.1.3.-based ORACLE_HOME used in Oracle E-Business Suite 12.x releases prior to 12.2.
The Web services component of Oracle Application Server processes requests received over the network from the desktop clients, and includes the following major components:
• Web Listener (Oracle HTTP Server powered by Apache)
The Web listener component of the Oracle HTTP server accepts incoming HTTP requests (for particular URLs) from client browsers, and routes the requests to WLS.
If possible, the Web server services the requests itself, for example by returning the HTML to construct a simple Web page. If the page referenced by the URL needs advanced processing, the listener passes the request on to the servlet engine, which contacts the database server as needed.
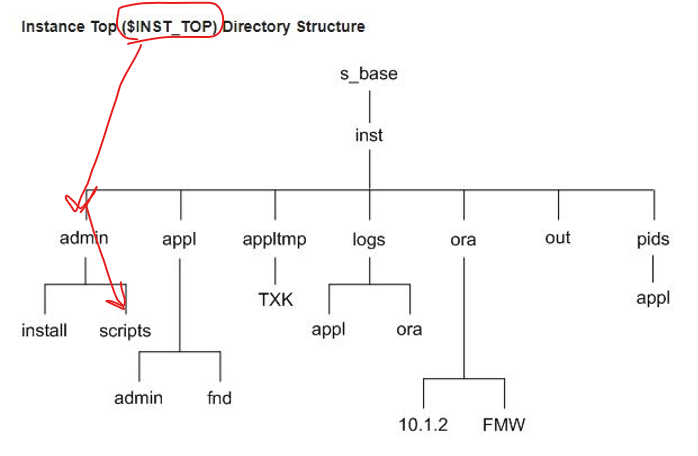
Instance Home
Like other 12.x releases, Oracle E-Business Suite Release 12.2 uses the concept of a top-level directory for an Oracle E-Business Suite instance. This directory is referred to as the Instance Home and denoted by the environment variable $INST_TOP. Using an Instance Home provides the ability to share application and technology stack code among multiple instances.
Prior to Release 12.2, all the configuration files modified by AutoConfig were located under $INST_TOP. The following parts of the file system could be made read-only: APPL_TOP, OracleAS 10.1.2 ORACLE_HOME, and OracleAS 10.1.3 ORACLE_HOME
In Release 12.2, the APPL_TOP and FMW_Home contain some configuration files modified by AutoConfig. Only the OracleAS 10.1.2 ORACLE_HOME configuration files are located under $INST_TOP, and so can be made read-only. The HTTP and Oracle WebLogic Server configuration files are not stored under the $INST_TOP.
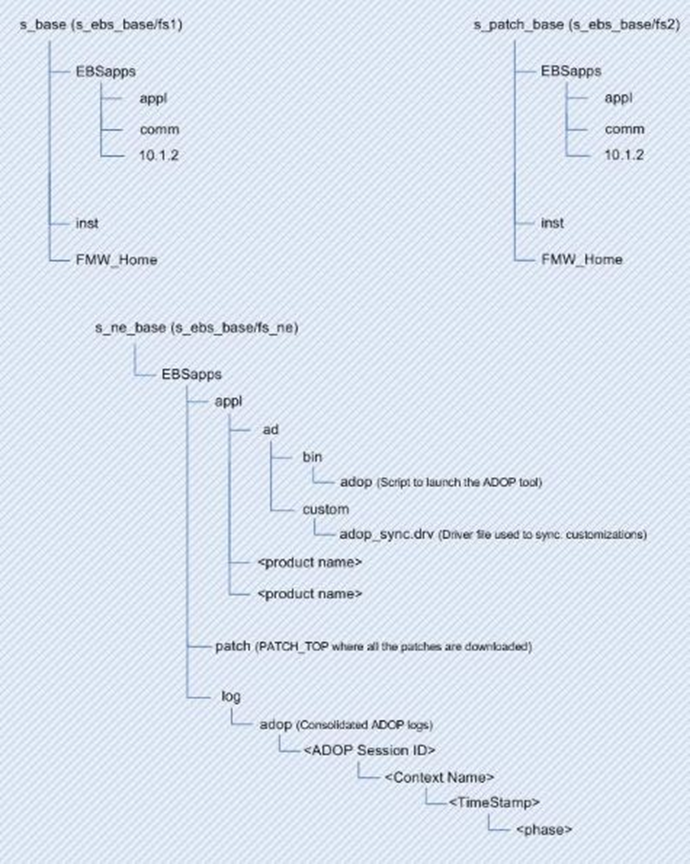
In a single-node application tier environment, the basic structure of the Instance Home is: <s_base>/inst/apps/<context_name>, where s_base (which does not have a corresponding environment variable) is the top level of the Oracle E-Business Suite installation, and <context_name> is the highest level at which the applications context exists. For example, $INST_TOP might be /u01/R122_EBS/fs1/inst/apps/ebstest , where ebstest is the context name.
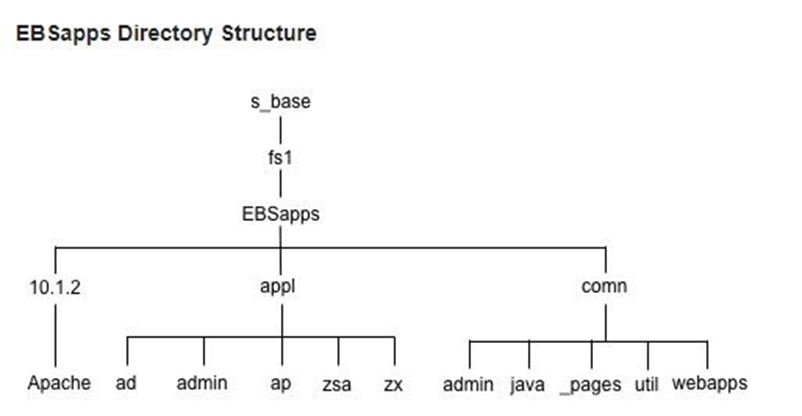
The EBSapps Directory
The EBSapps directory is another key high-level directory that was introduced in Oracle E-Business Suite Release 12.2. It will be located under a path with a name such as /u01/R122_EBS/fs1, at the same level as the inst directory.
The comn Directory
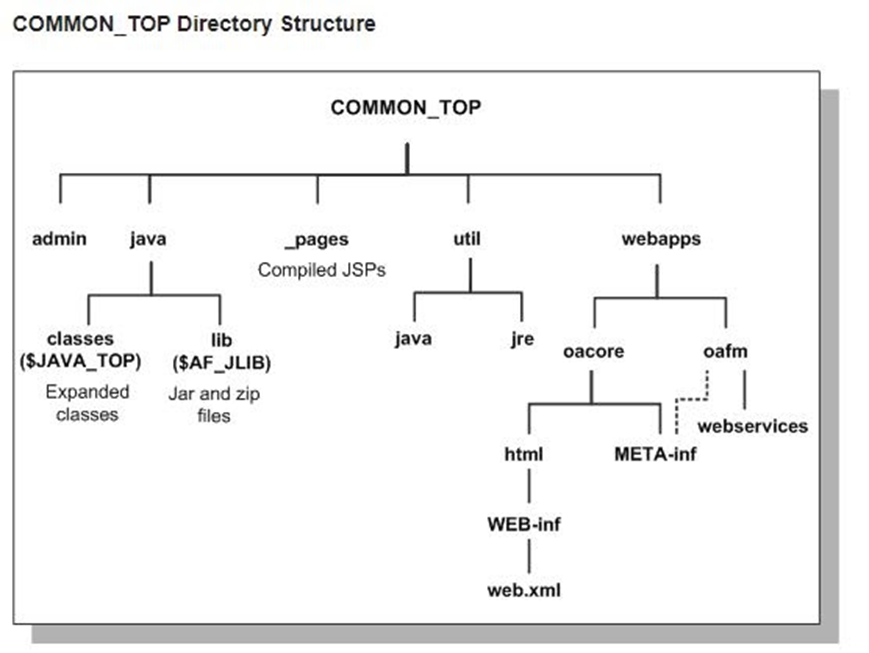
The EBSapps/comn (COMMON_TOP) directory contains files used by many different Oracle E-Business Suite products, and which may also be used with third-party products.
The admin directory
The admin directory, under the COMMON_TOP directory, is the default location for the concurrent manager log and output directories. When the concurrent managers run Oracle E-Business Suite reports, they write the log files and temporary files to the log subdirectory of the admin directory, and the output files to the out subdirectory of the admin directory.
The java directory
Rapid Install places all Oracle E-Business Suite class files in the COMMON_TOP/java/classes directory, pointed to by the $JAVA_TOP environment variable. Zip and jar files are installed in the $COMMON_TOP/java/lib directory, pointed to by the $AF_JLIB environment variable. The top-level Java directory, $COMMON_TOP/java, is pointed to by the $JAVA_BASE environment variable.
The util directory
The util directory contains additional utilities that ship with Oracle E-Business Suite. These include the Java Runtime Environment (JRE) and Java Development Kit (JDK).
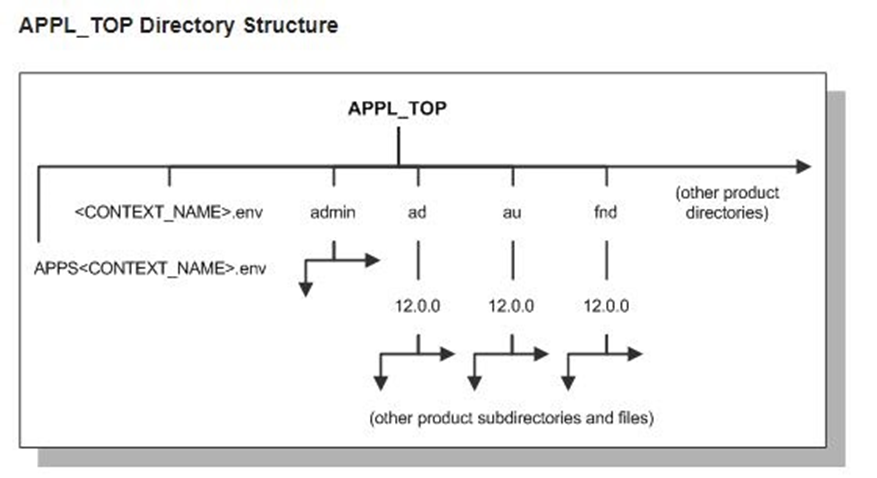
The appl Directory
Many Oracle E-Business Suite files are stored in the EBSapps/appl directory, which is generally known as the APPL_TOP.
The APPL_TOP directory contains:
The core technology files and directories.
The product files and directories (for all products).
The main Oracle E-Business Suite environment file, called <CONTEXT_NAME>.env on UNIX, and <CONTEXT_NAME>.cmd on Windows.
The consolidated environment file, called APPS<CONTEXT_NAME>.env on UNIX
Note: CONTEXT_NAME is the Oracle Applications context. Its default value is <SID>_<hostname>.
Rapid Install creates a directory tree for every Oracle E-Business Suite product in this APPL_TOP directory, whether licensed or not. Regardless of registration status, all Oracle E-Business Suite products are installed in the database and the file system.
Warning: Do not attempt to delete any files belonging to unregistered or unused products.
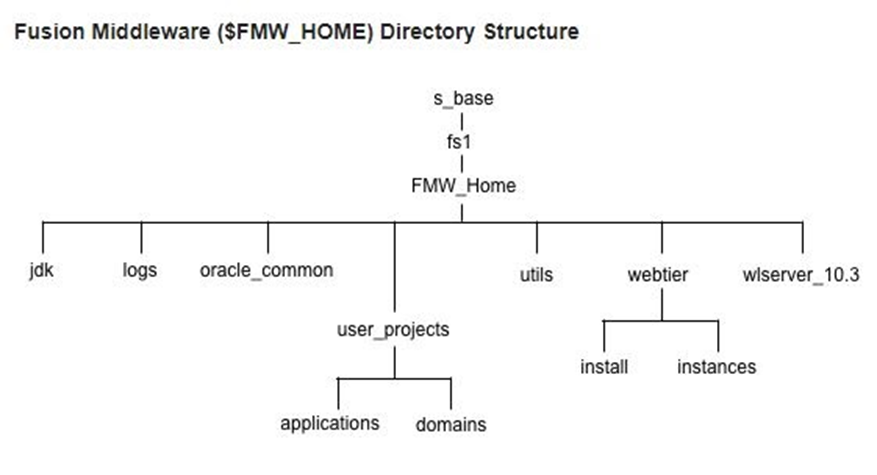
Fusion Middleware Home
The Oracle Fusion Middleware (FMW) directory is another key high-level directory. It is completely new in Oracle E-Business Suite Release 12.2, as this technology was not used in previous releases.
Typically, the FMW directory will be located in a path such as /u01/R122_EBS/fs1, at the same level as the inst and EBSapps directories. It includes subdirectories such as:
EBS_Domain: The Oracle WebLogic Server domain used to deploy Oracle E-Business Suite. All the domain-specific configuration and log files are located here.
Each node in a WLS domain has a Node Manager, which can be started and stopped using the $ADMIN_SCRIPTS_HOME/adnodemgrctl.sh script.
wlserver_10.3: Contains all the binaries and libraries required to support Oracle Weblogic Server.
oracle_common: Contains all the Java Required Files (JRFs) needed by Oracle E-Business Suite.
webtier: Contains the HTTP server instance used by EBS. All the HTTP-specific configuration and log files are located here.
Oracle_EBS-app1: Oracle E-Business Suite is deployed as an Oracle Home under FMW. This directory contains all the configuration files related to oacore, forms, oafm, and forms-c4ws.
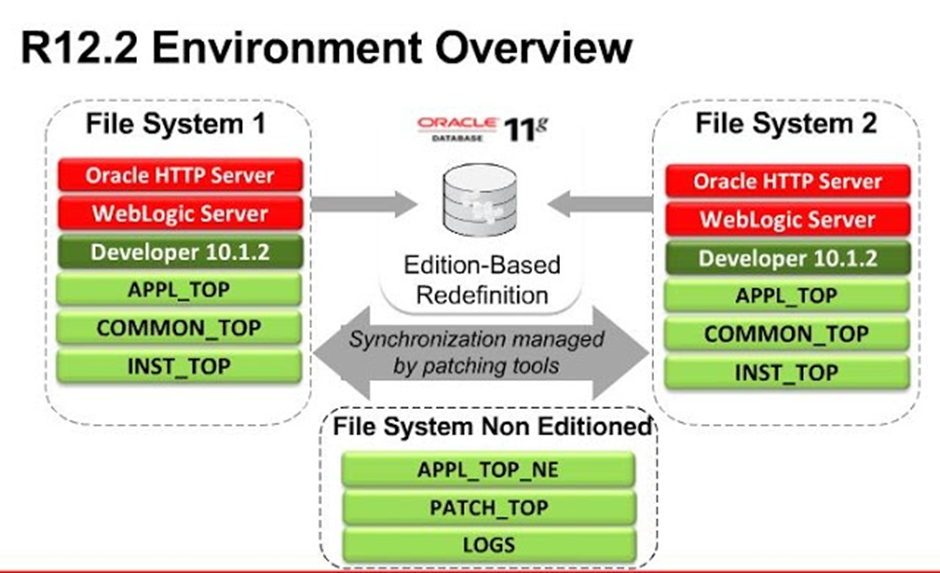
Dual and Non-Editioned File Systems
A key difference in Release 12.2 is the support needed for the new online patching mechanism.
Oracle E-Business Suite Release 12.2 uses a dual file system. At a given time, one file system (designated ‘run’) is part of the running system, while the other (designated ‘patch’) is either having patches applied or standing by in readiness for patch application. The two file systems are often referred to as fs1 and fs2.
Note: It is important to distinguish between the file system (fs1 or fs2) ) itself and its current role, which alternates between ‘patch’ and ‘run’ with every patching cycle.
As well as fs1 and fs2, there needs to be a non-editioned file system (fs_ne), which is used to store files containing data that is needed across all file systems.
The non-editioned file system is designed to store files which will never be changed by run and patch file system life cycles.The most notable examples of this are transactional data and certain log files.
Non-editioned files are not copied or moved during patching: their location remains constant across online patching cycles.
Files Stored in the Non-Editioned File System
The non-editioned file system is designed to store files that contain transactional data and reference data. Examples include: import, export files, general log files, and concurrent manager log and out files.These are all examples of files that are not modified during an online patching cycle.
More specialized examples include:
Batch upload and download files.
Files used to transfer transactional data from processes external to Oracle E-Business Suite (for example, where a third party order entry system delivers orders via order import files).
Files containing transactions that are needed across all file systems.
Note: The non-editioned file system is not designed to store shared files, because initially identical files can become non-identical during patching life cycles. Nor is it designed to store code, which is editioned (one copy can be in the run file system while the other is in the patch file system).
Concurrent Processing and the Non-Editioned File System
Concurrent processing in particular makes significant use of the non-editioned file system, with all concurrent manager log and out files being stored there.
Before Release 12.2, there were two choices for the location of log and out files. The first was $APPL_TOP, and the second was $APPLCSF (which pointed to $APPL_TOP/admin/$TWO_TASK). The location used was determined by whether the $APPLCSF environment variable was set.
With Release 12.2, the $APPL_TOP contains only code and configuration files. Therefore, it is mandatory for the $APPLCSF environment variable to be set. Its default value points to the non-editioned file system, specifically to <s_ne_base>/inst/<EBS_Instance_ID>/logs/appl/conc
for example, /u01/R122EBS/fs_ne/inst/app101/logs/appl/conc
app101 is instance id
/u01/R122EBS/fs_ne is <s_ne_base>
In addition, a new environment variable, $APPLLDM, has been introduced to provide the option of organizing storage of log and out files on a product-specific basis. In Release 12.2, $APPLLDM environment variable can have multiple possible values. The two main ones are ‘single’ and ‘product’.
‘single’ ( default) -> concurrent processing and AD Administration log files will both be stored under $APPLCSF/log. Concurrent processing out files will be stored under $APPLCSF/out.
‘product’ -> concurrent processing log and out files will be written to product-specific directories under $APPLCSF. This is in contrast to previous releases, where the directories were under $APPL_TOP.
Beginning with Release 12.2.6, Oracle E-Business Suite provides additional storage strategies for management of large numbers of concurrent processing log and output files. For example, concurrent request log and out files can be organized by date or by user name. These storage strategies are called schemes.
Oracle E-Business Suite Release 12.2 has seen significant changes to the locations under which log files are stored. In large part, this is because of the introduction of online patching and the additional file systems it employs. The adoption of Oracle WebLogic Server for some configuration management tasks has brought its own log file requirements, over and above those of the traditional AutoConfig tool.
$LOG_HOME
$LOG_HOME which translates to $INST_TOP/logs , this environment variable and its associated location are used in Release 12.2 as they were in previous releases. Most of the Oracle E-Business Suite log files are stored here, under $LOG_HOME/appl/admin/log. Examples include service control logs, AutoConfig logs, and runtime-generated logs.
A change in Release 12.2 is that HTTP, Oracle WebLogic Server, and concurrent processing log files are not stored under $LOG_HOME as they were in previous releases:
HTTP log files are located under the native instance home.
Oracle WebLogic Server log files are located under the domain home.
Concurrent processing log files are located on the non-editioned file system (fs_ne).
Patching Log Files
The adop log files for online patching are located on the non-editioned file system (fs_ne), under:
For more information, see ‘The adop Utility’ in the Patching Utilities chapter of Oracle E-Business Suite Maintenance Guide.
Configuration Log Files
The AutoConfig log files are stored under <INST_TOP>/admin/log/<MMDDhhmm> on the application tier, and <RDBMS_ORACLE_HOME>/appsutil/log/<CONTEXT_NAME>/<MMDDhhmm> on the database tier.
SUMMARY
fs1 (production file system) – Used by the current users of the system.
fs2 (Copy of production file system) – Used by the patching tools.
fs_ne (Non-editioned file system) – Stores files containing data that is needed across all file systems (for example, data import and export files, report output files, and log files).
Inst (INST_TOP) – Oracle E-Business Suite Release 12 Instance Home, contains all the config files, log files, SSL certificates etc.
All three file systems serve a single database. The file system that is currently being used by the running application is never patched: all patches are applied to the file system that is not currently in use.
It is optional to apply a patch with downtime, but it is more fast and it requires less system resources as it seems.. On the other hand; with downtime mode; you ‘ll have an increased system downtime..
As you know, in EBS 12.2; we dont have a maintanence mode anymore .. That’s why; to apply a patch with downtime , we only need to stop our application tier services..
With apply_mode=downtime ; adop directly applies the patch .. No patching cycles…
But we need to face the facts;
As Oracle states;
Release 12.2 patches are not normally tested in downtime mode.
Downtime mode is only supported for production use where explicitly documented, or when directed by Oracle Support or Development.
So unless Oracle supports say that “This patch can be applied using apply_mode=downtime”; you need to solve the problems you may face during the adop downtime patching , by yourself..
There are some examples for these kind of situations;
Is it supported to apply 17050005 R12.HR_PF.C.delta.4 in downtime mode ? (Doc ID 1916385.1) -> If customer is using AD-TXK Delta 5 or above, then it is supported to apply the patch R12.HR_PF.C.delta.4 (17050005) in downtime mode.
Is It Possible To Apply ALL Patches During An Upgrade From 11i To 12.2.4 With Apply_mode=downtime (Doc ID 1918842.1) -> Can all post-12.2.4 patches can be applied in downtime mode? Yes, all post-12.2.4 patches can be applied in downtime mode as long as the Applications Tier processes have not been started (first time after upgrade). Can downtime mode be used to apply patches once the upgrade is complete? No. Once the system is open for users, all subsequent patches must be applied on-line unless otherwise stated in the Readme or corresponding Note
Here another important doc: Oracle E-Business Suite Release 12.2.4 Readme (Doc ID 1617458.1) –> adop phase=apply apply_mode=downtime patches=17919161
Oracle suggests and supports this downtime apply mode for the fresh installations, upgrades and for some specific product upgrades at the moment;
When the system is started to be used by the users ; in other words when we put data into it/ when we start the business processes, we need to apply our patches online unless otherwise started in the Readme or corresponding note.
To be able to use dowtime mode; you need to upgrade AD-TXK Delta 5, or you need to upgrade to 12.2.4.. Note that you need to upgrade your AD-TXK DELTA 5 prior to 12.2.4 upgrade anyways
When you apply AD TXK Delta 5 as a prereq for 12.2.4, you may even use downtime mode during the application of your 12.2.4 upgrade patch.
For AD-TXK Delta 5 upgrade >
Applying the Latest AD and TXK Release Update Packs to Oracle E-Business Suite Release 12.2 (Doc ID 1617461.1)
For 12.2.4 Upgrade >
Oracle E-Business Suite Release 12.2.4 Readme (Doc ID 1617458.1)
EBS will remain available to users during patching operations
Online patching is supported by the capability of storing multiple application editions in the database, and the provision of a dual application tier file system. At any given point in time, one of these file systems is designated as run (part of the running system) and the other as patch (either being patched or awaiting the start of the next patching cycle).
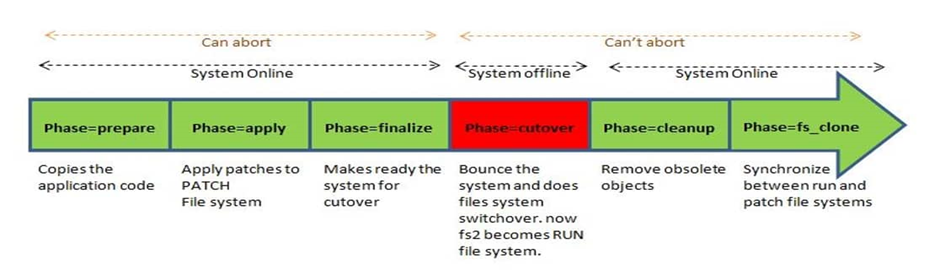
For applying a patch in R12.2 you need to use adop and run through all below phases in sequence mentioned below.
A) Set the environment by executing (sourcing) the run file system environment file:
$ source <EBS install base>/EBSapps.env run
B) Verify envirionment
You can confirm that the environment is properly set by examining the relevant environment variables:
$ echo $FILE_EDITION run
$ echo $TWO_TASK dbSID
C) Download Patches
Download patches to be applied and place then in the $PATCH_TOP directory of your system. This directory is pre-created by the install in the non-editioned file system (fs_ne) and should not be changed.
Important: On a multi-node system with non-shared file systems, you must copy the patch files to each separate $PATCH_TOP directory, so that the patch files are available from the same location on all nodes.
D) Unzip the patch
$ unzip <patch>.zip
E) Run Prepare Command
Prepare the system for patching by running the following command to start a new patching cycle:
$ adop phase=prepare
What it will do:
• Checks whether to perform a cleanup, which will be needed if the user failed to invoke cleanup after the cutover phase of a previous online patching cycle.
• Checks the integrity of the database data dictionary. If any corruption is found, adop exits with an error.
• Checks system configuration on each application tier node. A number of critical settings are validated to ensure that each application tier node is correctly registered, configured, and ready for patching.
• Checks for the existence of the “Online Patching In Progress” (ADZDPATCH) concurrent program. This program prevents certain predefined concurrent programs from being started, and as such needs to be active while a patching cycle is in progress (that is, while a database patch edition exists). If the ADZDPATCH program has not yet been requested to run, a request is submitted.
Note: ADZDPATCH is cancelled later on when the cutover phase is complete.
• Checks to see if the patch service has been created. adop requires that a special database service exists for the purpose of connecting to the patch edition. This service is created automatically, but its continued existence is validated on each prepare.
It can be checked by the database parameter SERVICE_NAME
SQL> show parameter service_name NAME TYPE VALUE ———————————— ———– ————— service_names string dba, ebs_patch
Here dba is the SID of our database and ebs_patch is additional service_name which is required by online patching tool.
If you look at tnsnames.ora file in the Application tier $TNS_ADMIN directory you will find below kind of entry:
During patching phase, adop will use this tns entry to connect to database.
• Invokes the TXK script $AD_TOP/patch/115/bin/txkADOPPreparePhaseSynchronize.pl to synchronize the patches which have been applied to the run APPL_TOP, but not the patch APPL_TOP.
• Checks the database for the existence of a patch edition, and creates one if it does not find one.
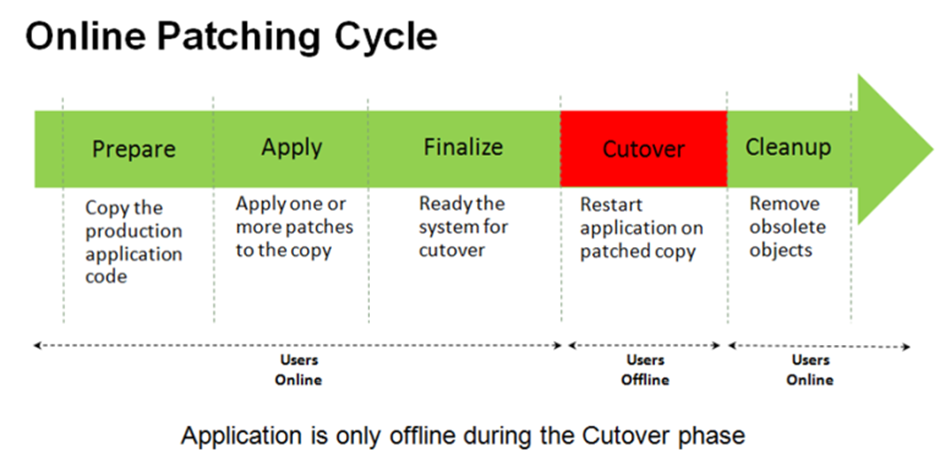
The finalize phase will be executed while the application is still online. It is used to perform any remaining processing that is needed to ensure the system is ready for the fastest possible cutover.
Used to perform the final patching operations that can
How to execute:
$ adop phase=finalize
What it will do:
• Pre-compute DDL that needs to be run at cutover.
• Compile all invalid objects.
• Validate that the system is ready for cutover.
If finalize_mode=full, compute statistics for key data dictionary tables for improved
performance.
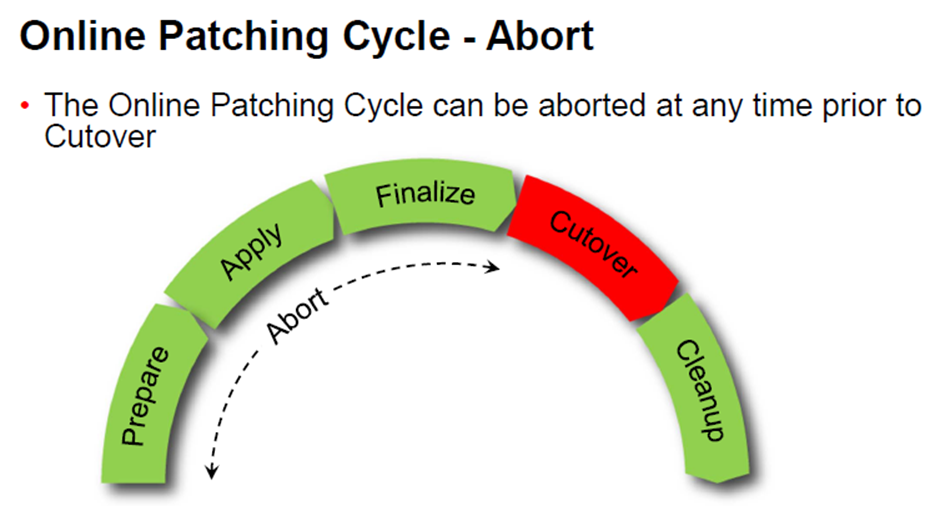
VERY IMPORTANT 1 : Up to this phase, you can run a special phase called abort, which will undo the changes made so far in the patching cycle. After cutover is complete, however, you cannot do this.
VERY IMPORTANT 2 : In an online patching cycle, the requisite JAR files are initially stored in the $APPL_TOP/admin/<SID>/out directory, and then uploaded into the database during the cut over phase. Therefore, the out directory must not be deleted at least until cut over (next phase) is complete.
4) CUTOVER PHASE DETAILS
Used to perform the transition to the patched environment. Shuts down application tier services, makes the patch edition the new run edition, and then restarts application tier services. This is the only phase the involves a brief downtime.
Important: No users should remain on the system during cutover, as there will be a short downtime period while the application tier services are restarted. Also, any third-party processes connected to the
old run edition of the database should be shut down, or they will be terminated automatically.
How to execute:
$ adop phase=cutover
What it will do:
• Shut down internal concurrent manager. The adop utility signals the internal concurrent manager to shut down, but will wait for any existing concurrent requests to finish before it proceeds with cutover actions.
Note: Cutover will take longer if it has to wait for long-running concurrent processes to complete. In such a case, you can expect to see an informational message of the form: [STATEMENT] [END 2013/10/28 23:47:16] Waiting for ICM to go downIf you do not want to wait for in-progress concurrent requests to finish normally, you can terminate the internal concurrent manager by executing the adcmctl.sh abort command from a different shell.
• Shut down application tier services: All application tier services are brought down. During this period, the system is unavailable to users.
• Cutover database: Promote patch database edition to become the new run database edition, using adzdpmgr.pl script.
• Cutover file system: Promote patch file system to become the new run file system, switching the $FILE_EDITION values in the patch and run enviroments. The current patch APPL_TOP becomes the new run APPL_TOP, and the current run APPL_TOP becomes the new patch APPL_TOP. Terminate old database sessions: Terminate any database connections to the old run edition of the database.
• Start application tier services: Application tier services are restarted, on the new run edition. The system is now available again to users
• ADZDPATCH concurrent program is cancelled when the cutover phase is complete.
Important: If you fail to run the cleanup phase explicitly, it will be run automatically on the next prepare cycle, but this will cause a delay in starting your next online patching cycle.
This adop phase is used to remove obsolete code and data from old editions.
How to execute:
$ adop phase=cleanup
What it will do:
• Various actions are performed during cleanup, including dropping (removing) obsolete: Crossedition triggers, Seed data, Editioned code objects (covered objects), Indexes, Columns, Editions.
Using parameter cleanup_mode:
a) cleanup_mode=quick – Performs minimum cleanup, including removal of obsolete crossedition triggers and seed data.
Use quick cleanup when you need to start the next patching cycle as soon as possible. For example, if you want to start a new patching cycle right away, but have not yet run cleanup from the previous patching cycle, you can use quick cleanup mode to complete the essential cleanup tasks as fast as possible.
b) cleanup_mode=standard – Does the same as quick mode, and also drops (removes) obsolete editioned code objects (covered objects).
This is the default mode , so does not need to be specified.
c) cleanup_mode=full – Performs maximum cleanup, which drops all obsolete code and data from earlier editions
Use full cleanup when you want to recover the maximum amount of space in the database. If you have run a large number of patching cycles, or applied a very large patch such as a rollup, significant space may be consumed by obsolete table columns and recovered by running a full cleanup. A full cleanup should only be performed when there is no immediate need to start a new patching cycle.
Abort PHASE is conditional phase. This phase cannot be specified with any other phase.
If for some reason either the prepare or apply phase failed or gave problems, you can abort the patching cycle at either of these points by running a special phase with the Command. The actions taken will be discarded (rollbacked).
IMPORTANT: This abort command is only available up to (but not including) the cutover phase. After cutover, the system is running on the new edition, and abort is no longer possible for that patching cycle.
How to execute:
The command to perform this operation is:
$ adop phase=abort
What it will do:
• Confirms that there is an in-progress online patching cycle, so the abort call is therefore valid.
• Checks for the existence of a patch edition and drops one if it exists.
• Cancels the ADZDPATCH concurrent program, if it is running.
• Deletes the rows inserted for the pending session ID from the ad_adop_sessions and ad_adop_session_patches tables.
VERY IMPORTANT: After running abort, a full cleanup must be performed. The cleanup command is: adop phase=cleanup cleanup_mode=full). This will remove any columns that were added by the patch but are no longer needed because of the abort. If they are not removed, they may cause problems in a later patching cycle.
Alternatively, you can run a combined command to abort the patching cycle and perform a full cleanup:
$ adop phase=abort,cleanup cleanup_mode=full
If any attempt was made to apply patches to the patch edition, after abort you must run the fs_clone phase (adop phase=fs_clone) to recreate the patch file system.
The fs_clone phase is a command (not related to adcfgclone.pl) that is used to synchronize the patch file system with the run file system. The fs_clone phase should only be run when mentioned as part of a specific documented procedure.
How to execute:
The fs_clone phase is run using the following command:
$ adop phase=fs_clone
What it will do:
This phase is useful if the APPL_TOPs have become very unsynchronized (meaning that there would be a large number of delta patches to apply). It is a heavyweight process, taking a backup of the entire current patch APPL_TOP and then cloning the run APPL_TOP to create a new patch APPL_TOP. As this method requires more time and disk space, it should only be used when the state of the patch file system is unknown. This command must be invoked from the run file system, before the next prepare phase is run.
Note: The patch file system requires at least 25 GB of free disk space to be available for adop operations, including fs_clone. If there is insufficient free space, the adop operation will fail.
If an fs_clone operation fails, you can rerun it with the option force=yes to restart it from the beginning (with the same session ID), or force=no to restart it from the point where it failed.
——————————————————————————————————————–
IMPORTANT POINTS REGARDING ONLINE PATCHING:
1. adop utility is put under $APPL_TOP_NE/ad/bin. It is a wrapper script which calls internally the perl script $AD_TOP/bin/adzdoptl.pl which does actual work of applying the patch.
2. adop will automatically set its environment as required, but it is the user’s responsibility to set the environment correctly for any other commands that may be run. Set the run edition environment whenever executing commands that you intend to affect the run edition.
For example:
$ . <EBS_ROOT>/EBSapps.env run $ adstrtal.sh
Set the patch edition environment whenever you intend to execute commands that affect the patch edition.
3. All the phases need to be completed and you can’t skip any of these. For example, if you try to skip prepare phase, you may get error message like “Apply phase can only be run while in a patching cycle, i.e. after prepare phase.”
4. After an online patching cycle is started, you should not perform any configuration changes in the run edition file system. Any that are made will not be propagated and will therefore be lost after cutover is complete.
5. You should not attempt to clone an Oracle E-Business Suite system while an online patching cycle is in progress.
6. The prepare, apply, and fs_clone phases all require at least 10GB of free disk space. All other phases require 1GB of free space. A warning message will be displayed if less than the needed amount is available.
7. The directories where you extracted the patches applied in a given patching cycle must be retained, in the same location and with the same contents, until the next prepare phase completes. This is also a requirement for patches applied in a hotpatch session.
8. Maintenance Mode is not needed for online patching, and so Maintenance Mode is not available in Oracle E-Business Suite Release 12.2.
——————————————————————————————————————-
ADOP ON MULTI-NODE
In a multi-node environment, one application tier node will be designated as the primary node. This is the node where the Admin Server is located, and will usually also be the node that runs Oracle HTTP Server. All other application tier nodes are designated as secondary nodes.
adop commands are invoked by a user on the primary node. Internally, adop uses Secure Shell (ssh) to automatically execute required patching actions on all secondary nodes. You must set up passwordless ssh connectivity from the primary node to all secondary nodes.
If a node unexpectedly becomes inaccessible via ssh, it will be abandoned by adop, and the appropriate further actions taken. Consider a scenario where the adop phase=prepare command is run in a system with ten application tier nodes. The command is successful on nine nodes, but fails on the tenth. In such a case, adop will identify the services enabled on nodes 1-9. If they are sufficient for Oracle E-Business Suite to continue to run normally, adop will mark node 10 as abandoned and then proceed with its patching actions. If they are not sufficient, adop will proceed no further.
PL/SQL NULL statement is a statement that does nothing. It serves as a placeholder statement when you need a syntactical construct in your code but don’t want to perform any actual action.
The PL/SQL NULL statement has the following format:
NULL;Code language: PostgreSQL SQL dialect and PL/pgSQL (pgsql)
The NULL statement is a NULL keyword followed by a semicolon ( ;). The NULL statement does nothing except that it passes control to the next statement.
The NULL statement is useful to:
Improve code readability
Provide a target for a GOTO statement
Create placeholders for subprograms
Using PL/SQL NULL statement to improve code readability
The following code sends an email to employees whose job titles are Sales Representative.
IF job_title = 'Sales Representative' THEN
send_email;
END IF;Code language: PostgreSQL SQL dialect and PL/pgSQL (pgsql)
What should the program do for employees whose job titles are not Sales Representative? You might assume that it should do nothing. Because this logic is not explicitly mentioned in the code, you may wonder if it misses something else.
To make it more clear, you can add a comment. For example:
-- Send email to only Sales Representative, -- for other employees, do nothing
IF job_title = 'Sales Representative' THEN
send_email;
END IF;Code language: PostgreSQL SQL dialect and PL/pgSQL (pgsql)
Or you can add an ELSE clause that consists of a NULL statement to clearly state that no action is needed for other employees.
IF job_title = 'Sales Representative' THEN
send_email;
ELSE
NULL;
END IF;Code language: PostgreSQL SQL dialect and PL/pgSQL (pgsql)
Similarly, you can use a NULL statement in the ELSE clause of a simple CASE statement as shown in the following example:
DECLARE
n_credit_status VARCHAR2( 50 );
BEGIN
n_credit_status := 'GOOD';
CASE n_credit_status
WHEN 'BLOCK' THEN
request_for_aproval;
WHEN 'WARNING' THEN
send_email_to_accountant;
ELSE
NULL;
END CASE;
END;
Code language: PostgreSQL SQL dialect and PL/pgSQL (pgsql)
In this example, if the credit status is not blocked or warning, the program does nothing.
Using PL/SQL NULL statement to provide a target for a GOTO statement
When using a GOTO statement, you need to specify a label followed by at least one executable statement.
The following example uses a GOTO statement to quickly move to the end of the program if no further processing is required:
DECLARE
b_status BOOLEAN
BEGIN
IF b_status THEN
GOTO end_of_program;
END IF;
-- further processing here-- ...
<<end_of_program>>
NULL;
END;Code language: PostgreSQL SQL dialect and PL/pgSQL (pgsql)
Note that an error will occur if you don’t have the NULL statement after the end_of_program label.
Creating placeholders for subprograms
The following example creates a procedure named request_for_approval that doesn’t have the code in the body yet. PL/SQL requires at least one executable statement in the body of the procedure in order to compile successfully, therefore, we add a NULL statement to the body as a placeholder. Later you can fill in the real code.
CREATE PROCEDURE request_for_aproval(
customer_id NUMBER
)
AS
BEGIN
NULL;
END;
The label_name is the name of a label that identifies the target statement. In the program, you surround the label name with double enclosing angle brackets as shown below:
PL/SQL GOTO Demo
Hello
and good Bye...
Code language: SQL (Structured Query Language) (sql)
The following explains the sequence of the block in detail:
First, the GOTO second_message statement is encountered, therefore, the control is passed to the statement after the second_message label.
Second, the GOTO first_message is encountered, so the control is transferred to the statement after the first_message label.
Third, the GOTO the_end is reached, the control is passed to the statement after the the_end label.
The picture below illustrates the sequence:
GOTO statement restrictions
The GOTO statement is subject to the following restrictions.
First, you cannot use a GOTO statement to transfer control into an IF, CASE or LOOP statement, the same for the sub-block.
The following example attempts to transfer control into an IF statement using a GOTO statement:
DECLARE
n_sales NUMBER;
n_tax NUMBER;
BEGIN
GOTO inside_if_statement;
IF n_sales > 0 THEN
<<inside_if_statement>>
n_tax := n_sales * 0.1;
END IF;
END;
Code language: SQL (Structured Query Language) (sql)
Oracle issued the following error:
PLS-00375: illegal GOTO statement; this GOTO cannot branch to label 'INSIDE_IF_STATEMENT'
Code language: SQL (Structured Query Language) (sql)
Second, you cannot use a GOTO statement to transfer control from one clause to another in the IF statement e.g., from IF clause to ELSIF or ELSE clause, or from one WHEN clause to another in the CASE statement.
The following example attempts to transfer control to a clause in the IF statement:
DECLARE
n_sales NUMBER;
n_commission NUMBER;
BEGIN
n_sales := 120000;
IF n_sales > 100000 THEN
n_commission := 0.2;
GOTO zero_commission;
elsif n_sales > 50000 THEN
n_commission := 0.15;
elsif n_sales > 20000 THEN
n_commission := 0.1;
ELSE
<<zero_commission>>
n_commission := 0;
END IF;
END;
Code language: SQL (Structured Query Language) (sql)
Oracle issued the following error.
PLS-00375: illegal GOTO statement; this GOTO cannot branch to label 'ZERO_COMMISSION'
Code language: SQL (Structured Query Language) (sql)
Third, you cannot use a GOTO statement to transfer control out of a subprogram or into an exception handler.
Fourth, you cannot use a GOTO statement to transfer control from an exception handler back into the current block.