Terraform terminologies.
Let’s start Terraform, and understand some key terminologies and concepts. Here are some fundamental terms and explanations.
- Provider: A provider is a plugin for Terraform that defines and manages resources for a specific cloud or infrastructure platform. Examples of providers include AWS, Azure, Google Cloud, and many others. You configure providers in your Terraform code to interact with the desired infrastructure platform.
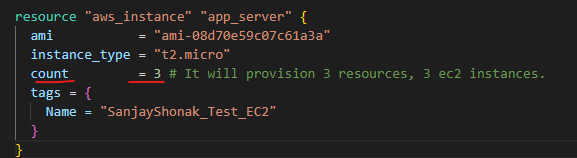
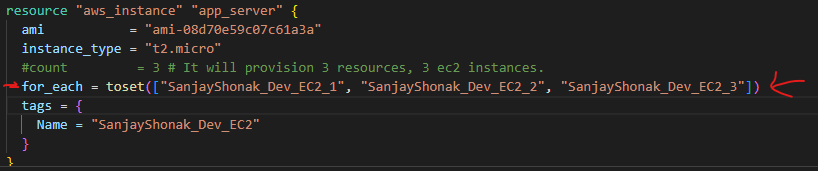
- Resource: A resource is a specific infrastructure component that you want to create and manage using Terraform. Resources can include virtual machines, databases, storage buckets, network components, and more. Each resource has a type and configuration parameters that you define in your Terraform code.
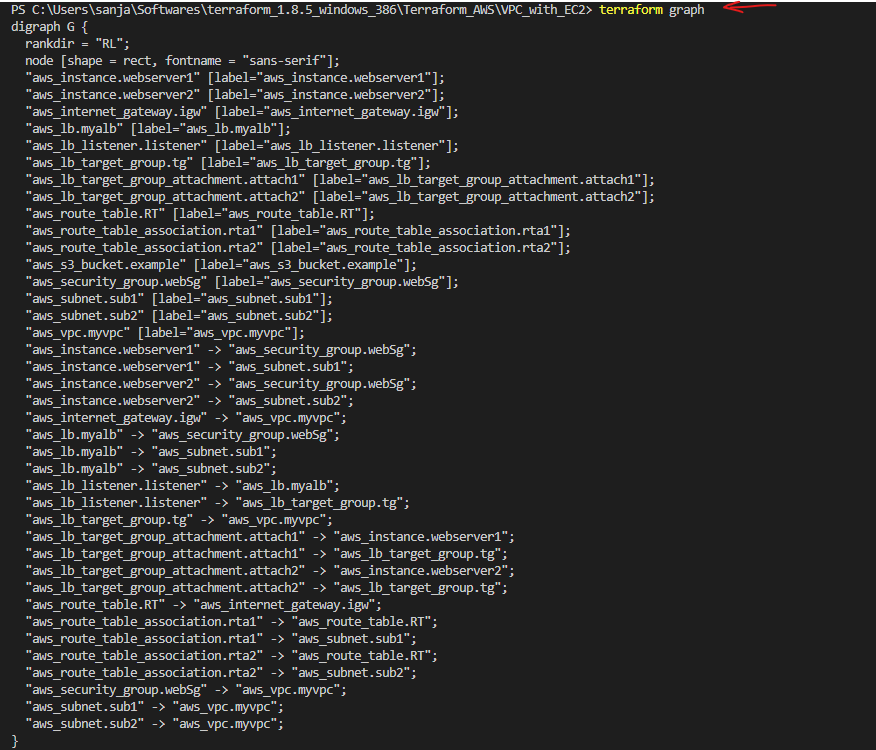
- Module: A module is a reusable and encapsulated unit of Terraform code. Modules allow you to package infrastructure configurations, making it easier to maintain, share, and reuse them across different parts of your infrastructure. Modules can be your own creations or come from the Terraform Registry, which hosts community-contributed modules.
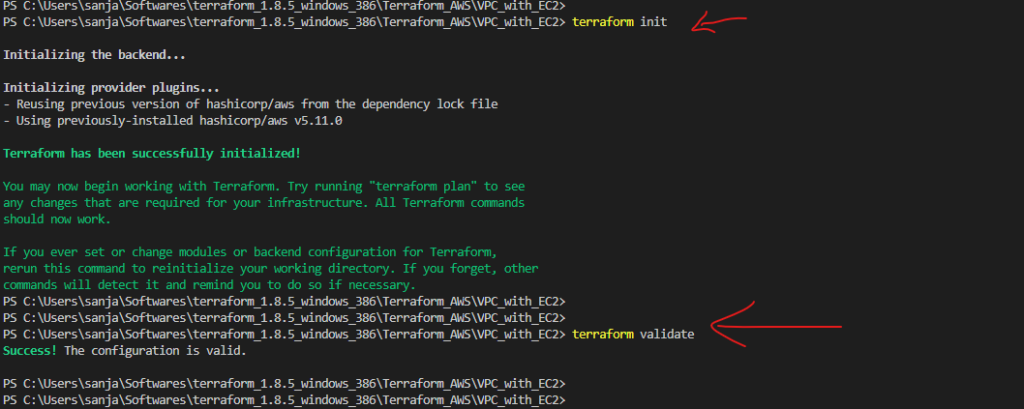
- Configuration File: Terraform uses configuration files (often with a
.tfextension) to define the desired infrastructure state. These files specify providers, resources, variables, and other settings. The primary configuration file is usually namedmain.tf, but you can use multiple configuration files as well. - Variable: Variables in Terraform are placeholders for values that can be passed into your configurations. They make your code more flexible and reusable by allowing you to define values outside of your code and pass them in when you apply the Terraform configuration.
- Output: Outputs are values generated by Terraform after the infrastructure has been created or updated. Outputs are typically used to display information or provide values to other parts of your infrastructure stack.
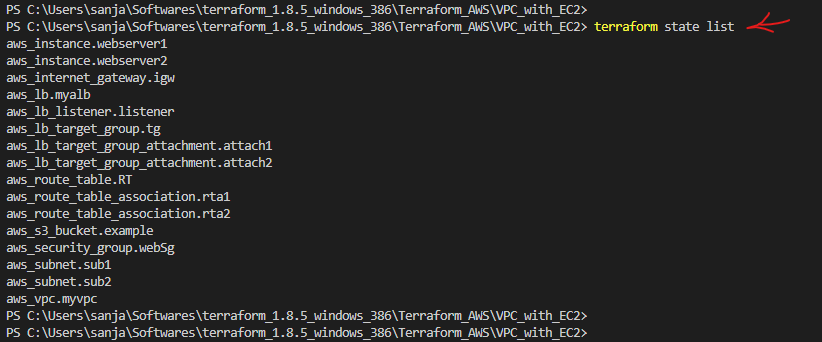
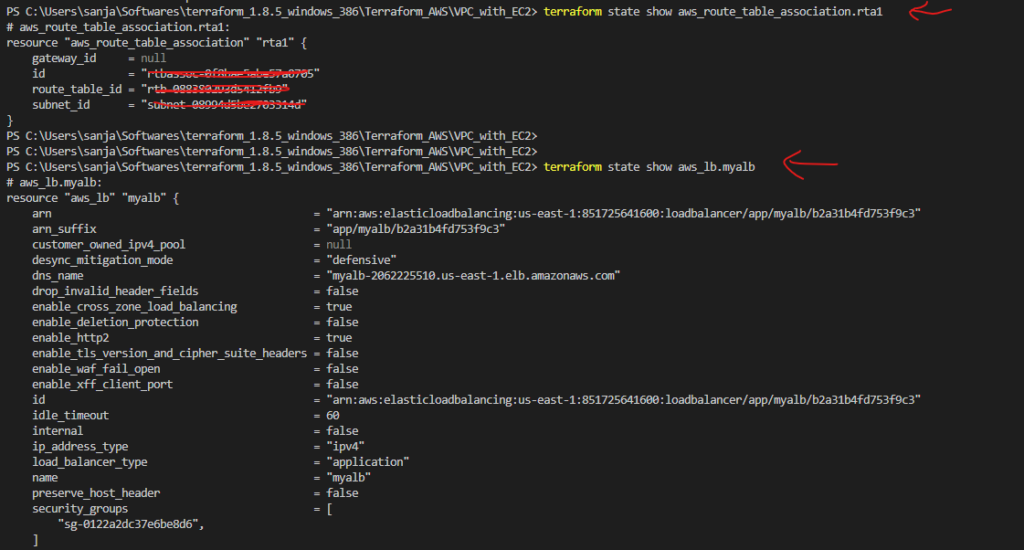
- State File: Terraform maintains a state file (often named
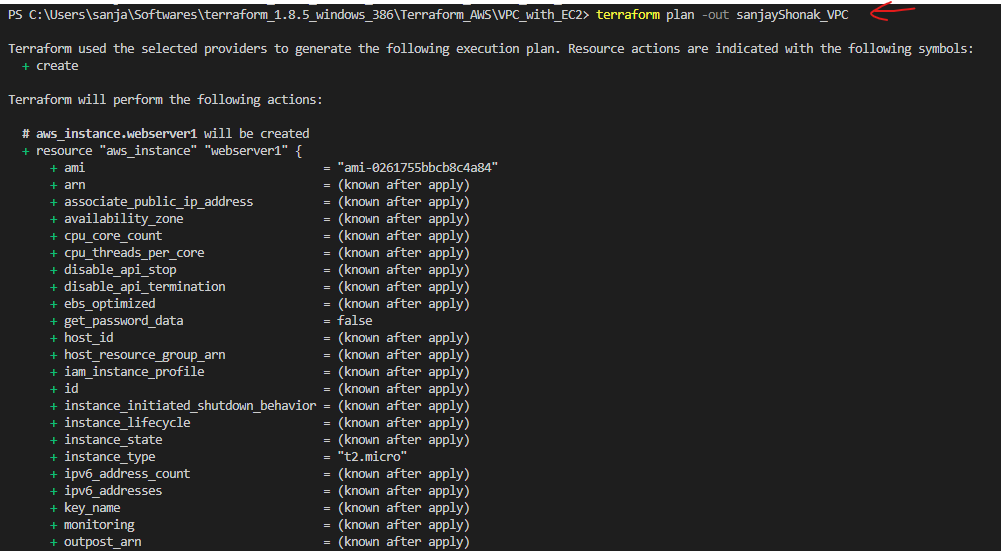
terraform.tfstate) that keeps track of the current state of your infrastructure. This file is crucial for Terraform to understand what resources have been created and what changes need to be made during updates. - Plan: A Terraform plan is a preview of changes that Terraform will make to your infrastructure. When you run
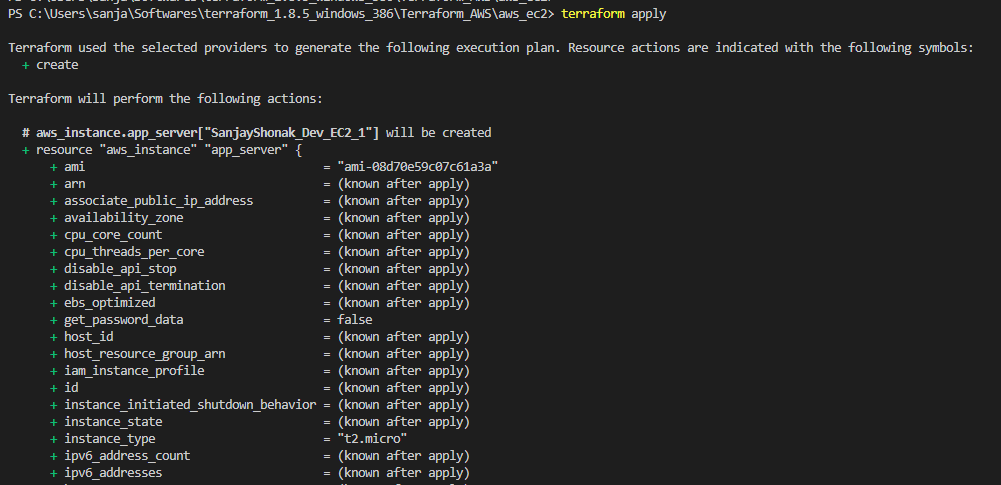
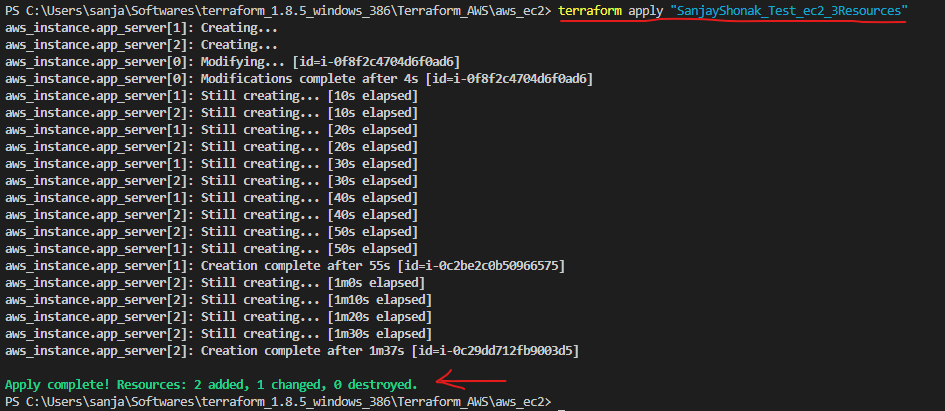
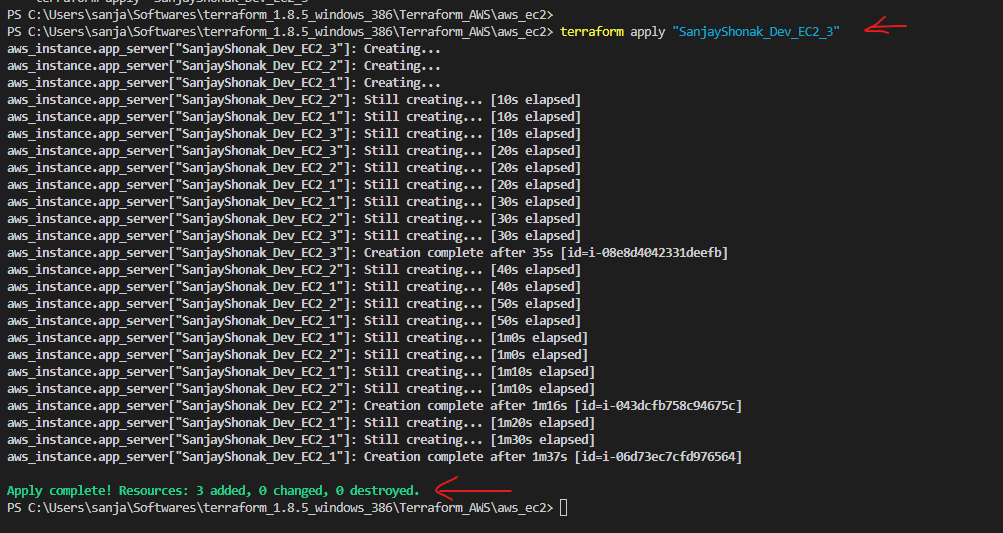
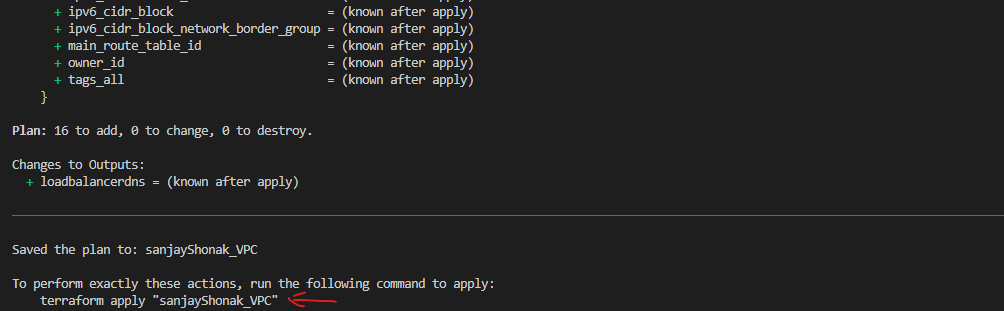
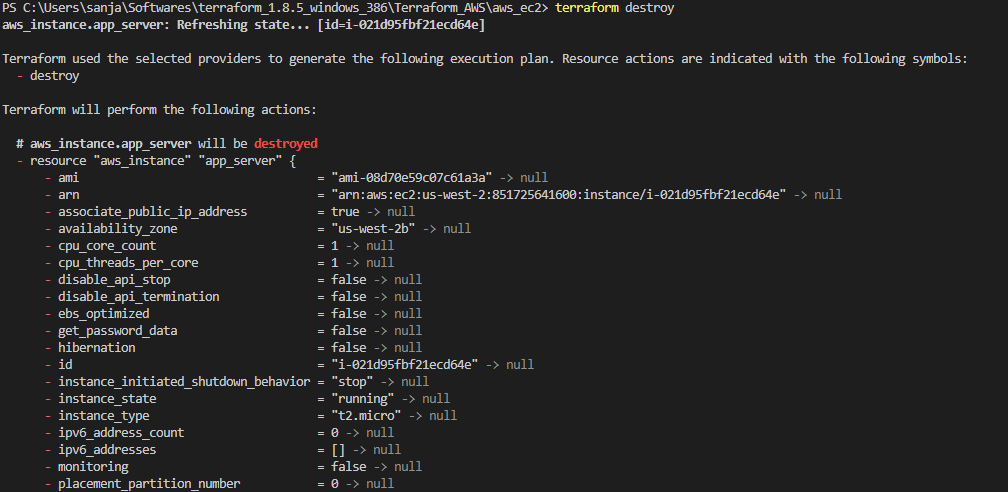
terraform plan, Terraform analyzes your configuration and current state, then generates a plan detailing what actions it will take during theapplystep. - Apply: The
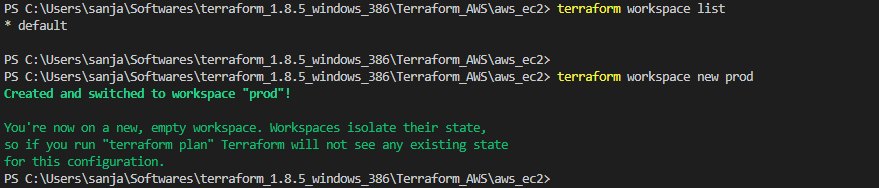
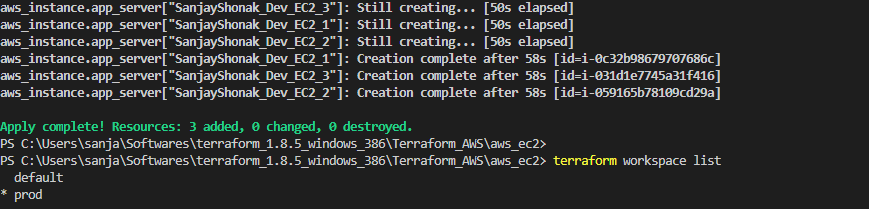
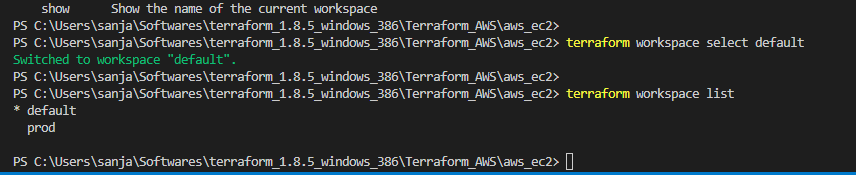
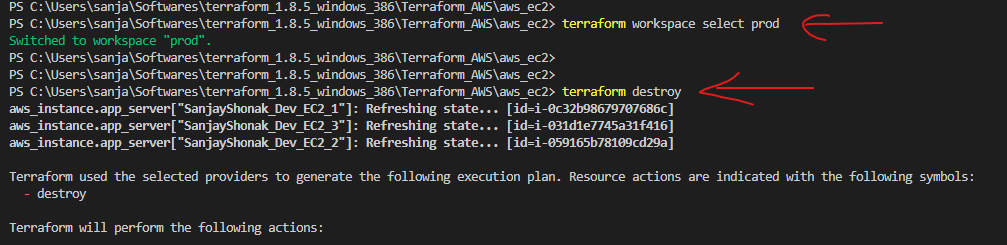
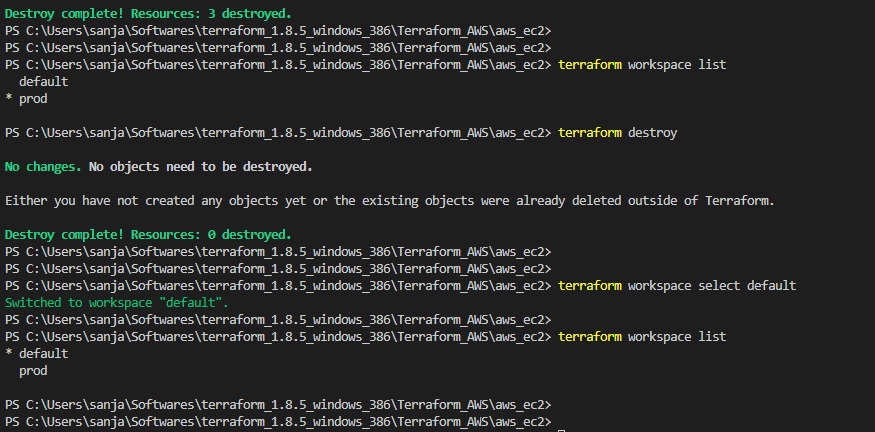
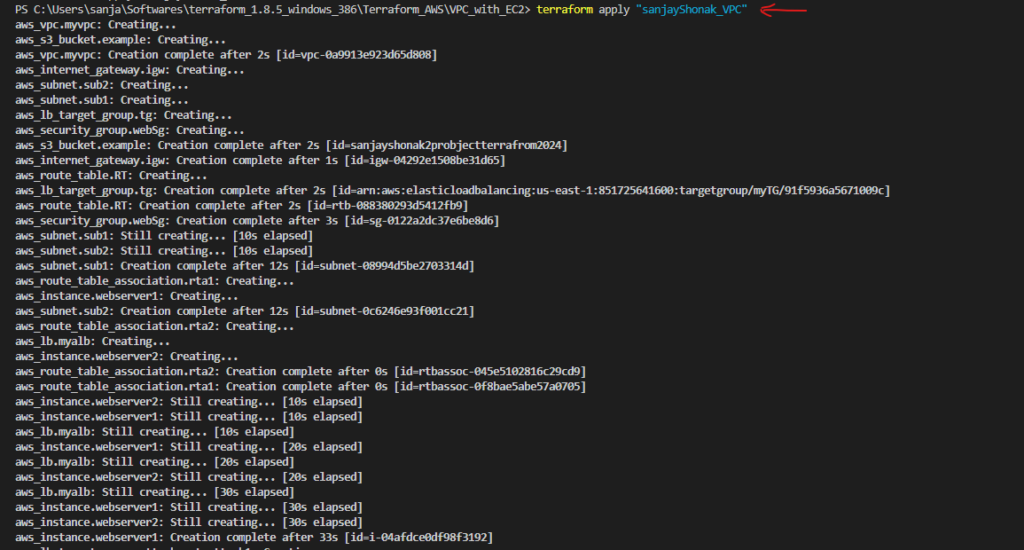
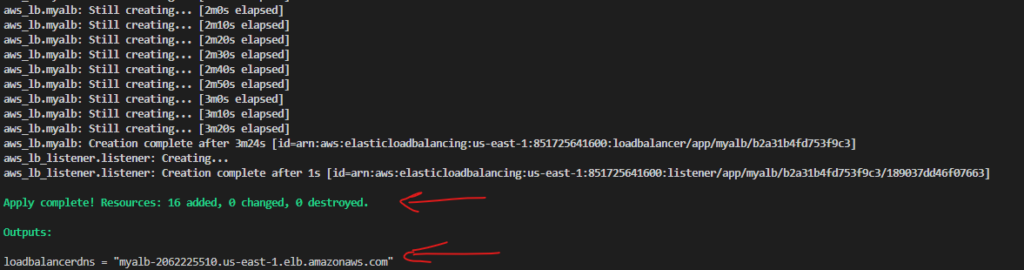
terraform applycommand is used to execute the changes specified in the plan. It creates, updates, or destroys resources based on the Terraform configuration. - Workspace: Workspaces in Terraform are a way to manage multiple environments (e.g., development, staging, production) with separate configurations and state files. Workspaces help keep infrastructure configurations isolated and organized.
- Remote Backend: A remote backend is a storage location for your Terraform state files that is not stored locally. Popular choices for remote backends include Amazon S3, Azure Blob Storage, or HashiCorp Terraform Cloud. Remote backends enhance collaboration and provide better security and reliability for your state files.
These are some of the essential terms you’ll encounter when working with Terraform. As you start using Terraform for your infrastructure provisioning and management, you’ll become more familiar with these concepts and how they fit together in your IaC workflows.
Why Terraform ?
There are multiple reasons why Terraform is used over the other IaC tools but below are the main reasons.
- Multi-Cloud Support: Terraform is known for its multi-cloud support. It allows you to define infrastructure in a cloud-agnostic way, meaning you can use the same configuration code to provision resources on various cloud providers (AWS, Azure, Google Cloud, etc.) and even on-premises infrastructure. This flexibility can be beneficial if your organization uses multiple cloud providers or plans to migrate between them.
- Large Ecosystem: Terraform has a vast ecosystem of providers and modules contributed by both HashiCorp (the company behind Terraform) and the community. This means you can find pre-built modules and configurations for a wide range of services and infrastructure components, saving you time and effort in writing custom configurations.
- Declarative Syntax: Terraform uses a declarative syntax, allowing you to specify the desired end-state of your infrastructure. This makes it easier to understand and maintain your code compared to imperative scripting languages.
- State Management: Terraform maintains a state file that tracks the current state of your infrastructure. This state file helps Terraform understand the differences between the desired and actual states of your infrastructure, enabling it to make informed decisions when you apply changes.
- Plan and Apply: Terraform’s “plan” and “apply” workflow allows you to preview changes before applying them. This helps prevent unexpected modifications to your infrastructure and provides an opportunity to review and approve changes before they are implemented.
- Community Support: Terraform has a large and active user community, which means you can find answers to common questions, troubleshooting tips, and a wealth of documentation and tutorials online.
- Integration with Other Tools: Terraform can be integrated with other DevOps and automation tools, such as Docker, Kubernetes, Ansible, and Jenkins, allowing you to create comprehensive automation pipelines.
- HCL Language: Terraform uses HashiCorp Configuration Language (HCL), which is designed specifically for defining infrastructure. It’s human-readable and expressive, making it easier for both developers and operators to work with.