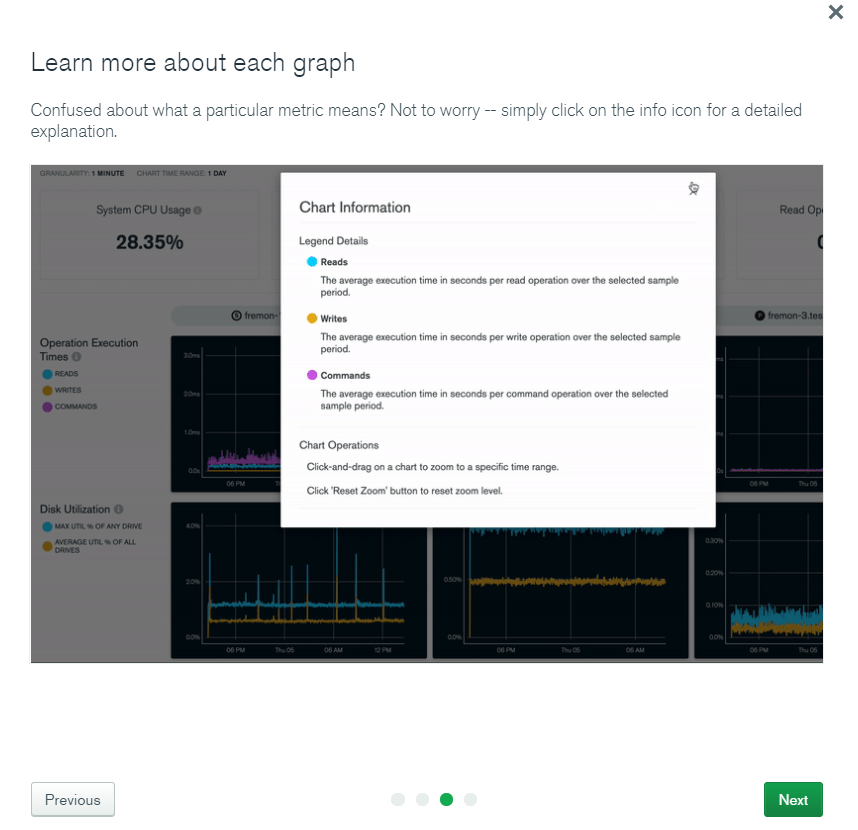
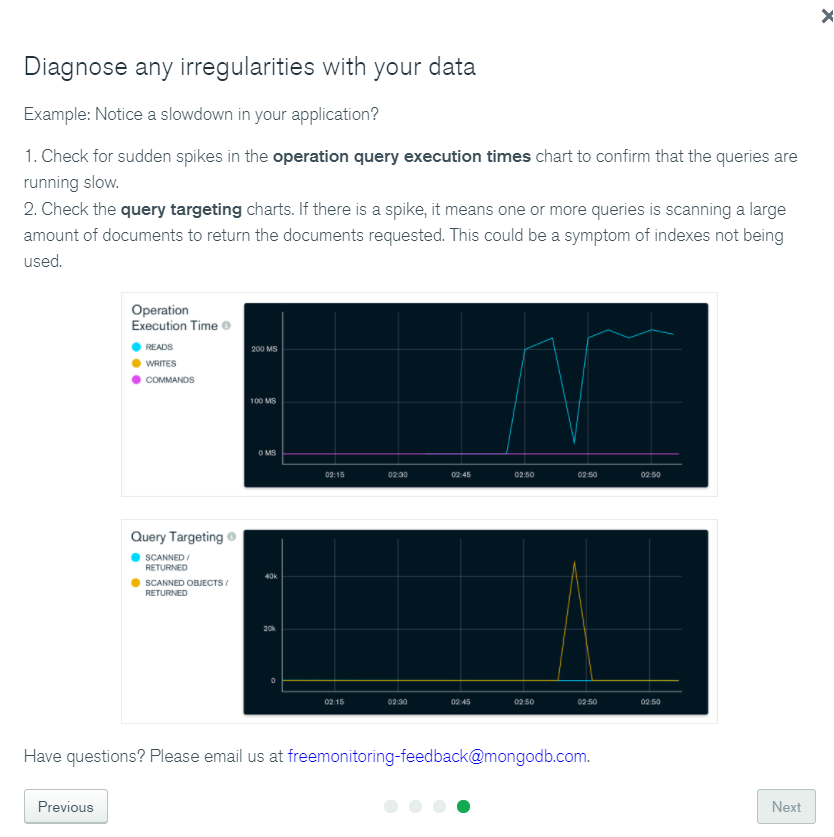
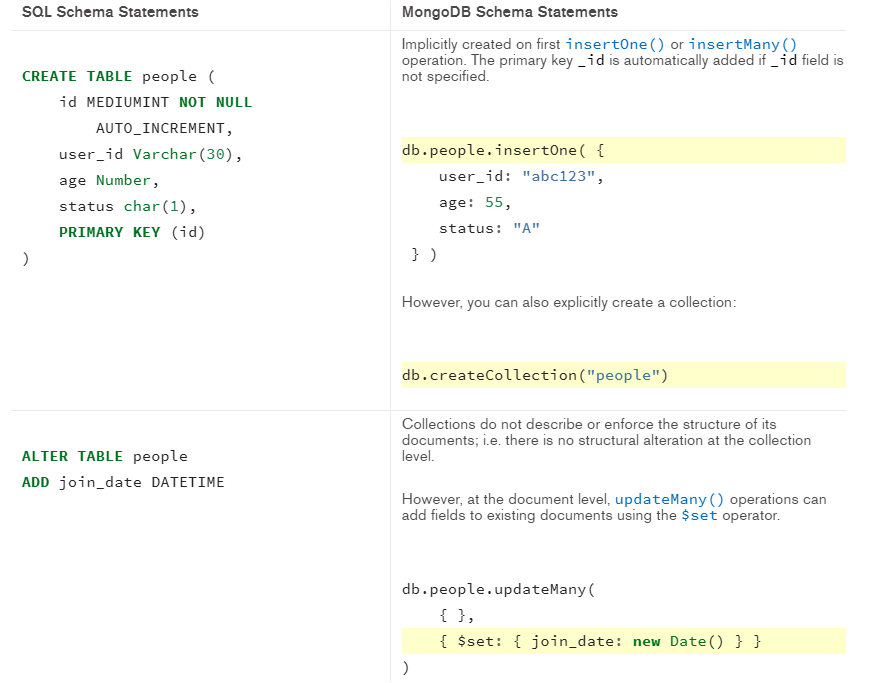
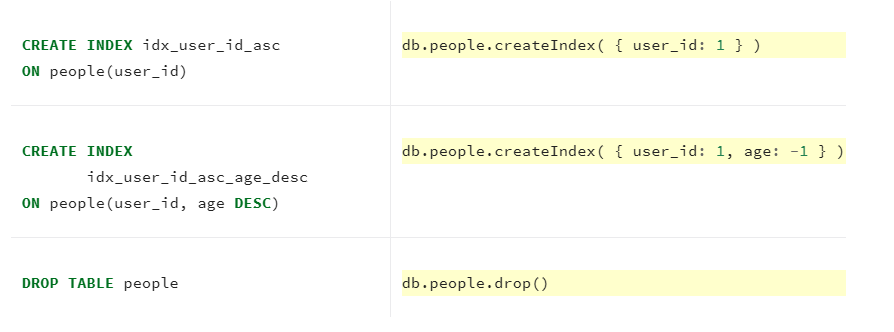
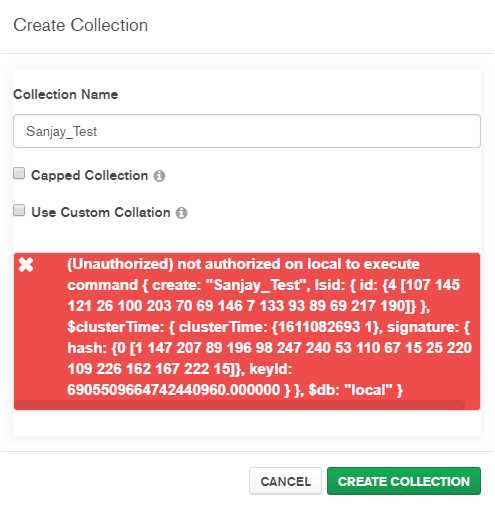
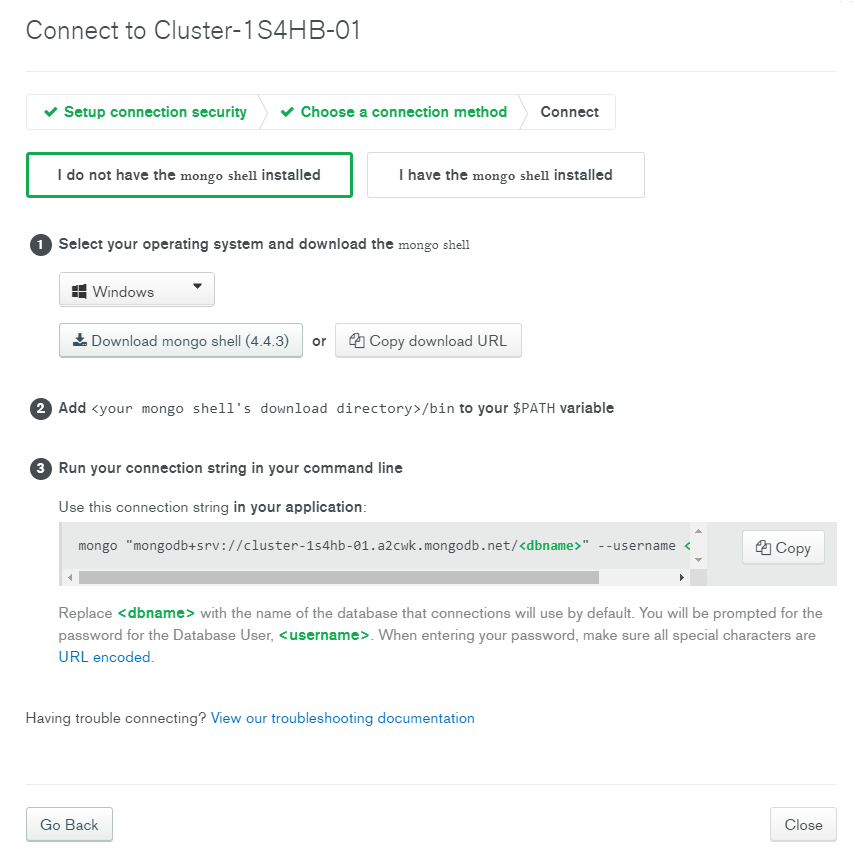
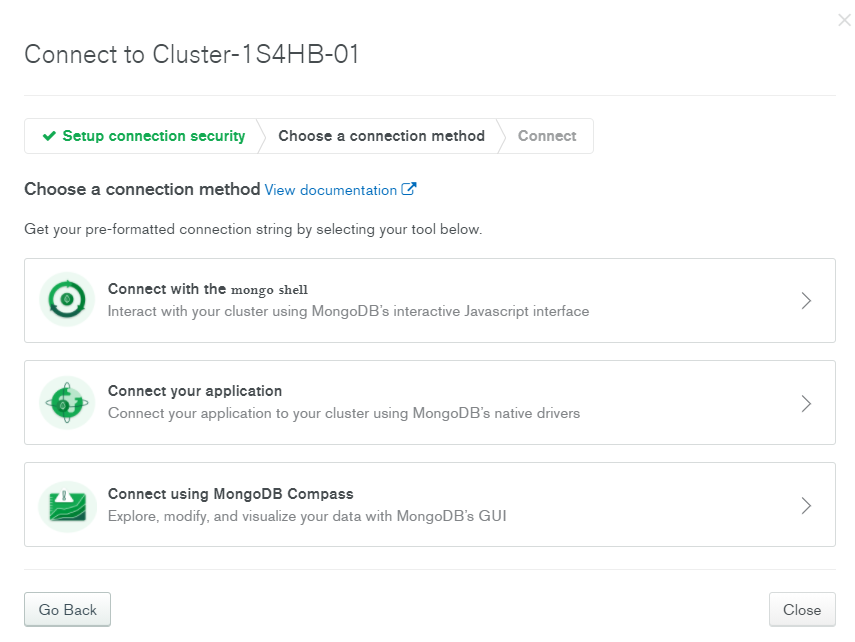
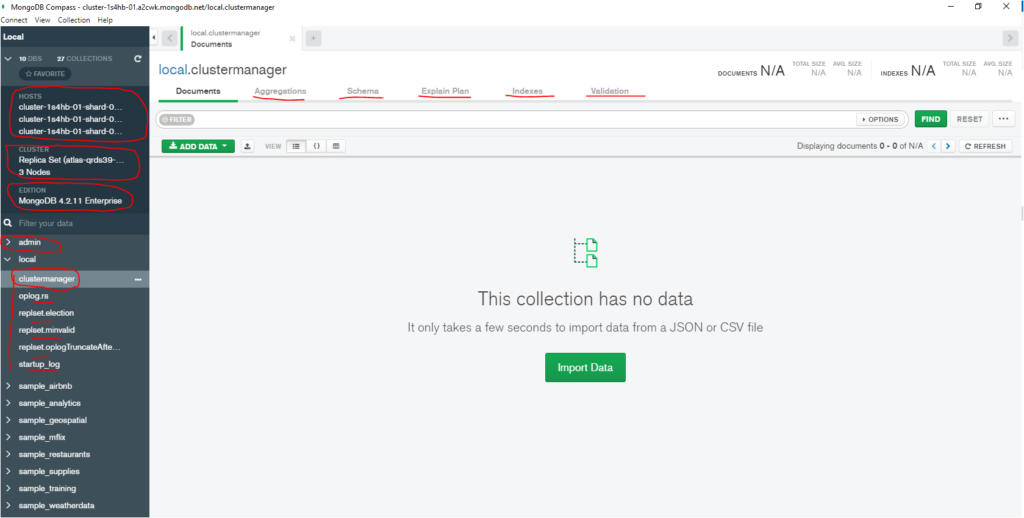
- Databases information.
SELECT db.datname, au.rolname as datdba,
pg_encoding_to_char(db.encoding) as encoding,
db.datallowconn, db.datconnlimit, db.datfrozenxid,
tb.spcname as tblspc,
— db.datconfig,
db.datacl
FROM pg_database db
JOIN pg_authid au ON au.oid = db.datdba
JOIN pg_tablespace tb ON tb.oid = db.dattablespace
ORDER BY 1;
Sample output

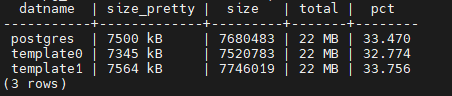
2. Databases space info
SELECT datname,
pg_size_pretty(pg_database_size(datname))as size_pretty,
pg_database_size(datname) as size,
(SELECT pg_size_pretty (SUM( pg_database_size(datname))::bigint)
FROM pg_database) AS total,
((pg_database_size(datname) / (SELECT SUM( pg_database_size(datname))
FROM pg_database) ) *
100)::numeric(6,3) AS pct
FROM pg_database ORDER BY datname;
Sample output:
3. Cash hit ratio
SELECT pg_stat_database.datname, pg_stat_database.blks_read, pg_stat_database.blks_hit,
round((pg_stat_database.blks_hit::double precision / (pg_stat_database.blks_read
+ pg_stat_database.blks_hit
+1)::double precision * 100::double precision)::numeric, 2) AS
cachehitratio
FROM pg_stat_database
WHERE pg_stat_database.datname !~ '^(template(0|1)|postgres)$'::text
ORDER BY round((pg_stat_database.blks_hit::double precision
/ (pg_stat_database.blks_read
+ pg_stat_database.blks_hit
+ 1)::double precision * 100::double precision)::numeric, 2) DESC;Sample output:

4. Blocking issue.
SELECT blocked_locks.pid AS blocked_pid, blocked_activity.usename AS blocked_user, blocking_locks.pid AS blocking_pid, blocking_activity.usename AS blocking_user, blocked_activity.query AS blocked_statement, blocking_activity.query AS current_statement_in_blocking_process FROM pg_catalog.pg_locks AS blocked_locks JOIN pg_catalog.pg_stat_activity AS blocked_activity ON blocked_activity.pid = blocked_locks.pid JOIN pg_catalog.pg_locks AS blocking_locks ON blocking_locks.locktype = blocked_locks.locktype AND blocking_locks.database IS NOT DISTINCT FROM blocked_locks.database AND blocking_locks.relation IS NOT DISTINCT FROM blocked_locks.relation AND blocking_locks.page IS NOT DISTINCT FROM blocked_locks.page AND blocking_locks.tuple IS NOT DISTINCT FROM blocked_locks.tuple AND blocking_locks.virtualxid IS NOT DISTINCT FROM blocked_locks.virtualxid AND blocking_locks.transactionid IS NOT DISTINCT FROM blocked_locks.transactionid AND blocking_locks.classid IS NOT DISTINCT FROM blocked_locks.classid AND blocking_locks.objid IS NOT DISTINCT FROM blocked_locks.objid AND blocking_locks.objsubid IS NOT DISTINCT FROM blocked_locks.objsubid AND blocking_locks.pid != blocked_locks.pid JOIN pg_catalog.pg_stat_activity blocking_activity ON blocking_activity.pid = blocking_locks.pid WHERE NOT blocked_locks.granted;
Sample output.

5. Total connections count.
SELECT COUNT() FROM pg_stat_activity; SELECT usename, count() FROM pg_stat_activity GROUP BY 1 ORDER BY 1;
SELECT datname, usename, count() FROM pg_stat_activity GROUP BY 1, 2 ORDER BY 1, 2; SELECT usename, datname, count() FROM pg_stat_activity GROUP BY 1, 2 ORDER BY 1, 2;
Sample output:
6. Stats of all tables.
SELECT n.nspname, s.relname, c.reltuples::bigint,– n_live_tup,
n_tup_ins, n_tup_upd, n_tup_del,
date_trunc(‘second’, last_vacuum) as last_vacuum,
date_trunc(‘second’, last_autovacuum) as last_autovacuum, date_trunc(‘second’,
last_analyze) as last_analyze, date_trunc(‘second’, last_autoanalyze) as last_autoanalyze
, round( current_setting(‘autovacuum_vacuum_threshold’)::integer +
current_setting(‘autovacuum_vacuum_scale_factor’)::numeric * C.reltuples) AS av_threshold
/* ,CASE WHEN reltuples > 0
THEN round(100.0 * n_dead_tup / (reltuples))
ELSE 0
END AS pct_dead,
CASE WHEN n_dead_tup > round( current_setting(‘autovacuum_vacuum_threshold’)::integer +
current_setting(‘autovacuum_vacuum_scale_factor’)::numeric * C.reltuples)
THEN ‘VACUUM’
ELSE ‘ok’
END AS “av_needed”
*/
FROM pg_stat_all_tables s
JOIN pg_class c ON c.oid = s.relid
JOIN pg_namespace n ON (n.oid = c.relnamespace)
WHERE s.relname NOT LIKE ‘pg_%’
AND s.relname NOT LIKE ‘sql_%’
— AND s.relname LIKE ‘%TBL%’
ORDER by 1, 2;
sample output:

7. Stats of all indexes.
SELECT n.nspname as schema, i.relname as table, i.indexrelname as index,
i.idx_scan, i.idx_tup_read, i.idx_tup_fetch,
CASE WHEN idx.indisprimary
THEN ‘pkey’
WHEN idx.indisunique
THEN ‘uidx’
ELSE ‘idx’
END AS type,
CASE WHEN idx.indisvalid
THEN ‘valid’
ELSE ‘INVALID’
END as statusi,
pg_relation_size( quote_ident(n.nspname) || ‘.’ || quote_ident(i.relname) ) as size_in_bytes,
pg_size_pretty(pg_relation_size(quote_ident(n.nspname) || ‘.’ || quote_ident(i.relname) )) as
size
FROM pg_stat_all_indexes i
JOIN pg_class c ON (c.oid = i.relid)
JOIN pg_namespace n ON (n.oid = c.relnamespace)
JOIN pg_index idx ON (idx.indexrelid = i.indexrelid )
WHERE i.relname LIKE ‘%%’
AND n.nspname NOT LIKE ‘pg_%’
— AND idx.indisunique = TRUE
— AND NOT idx.indisprimary
— AND i.indexrelname LIKE ‘tmp%’
— AND idx.indisvalid IS false
/* AND NOT idx.indisprimary
AND NOT idx.indisunique
AND idx_scan = 0
*/ ORDER BY 1, 2, 3;
sample output

8. Removing issues causing bloat.
Bloat can be caused by long-running queries or long-running write transactions that execute alongside write-heavy workloads.
Resolving that is mostly down to understanding the workloads running on the server.
Look at the age of the oldest snapshots that are running, like this:
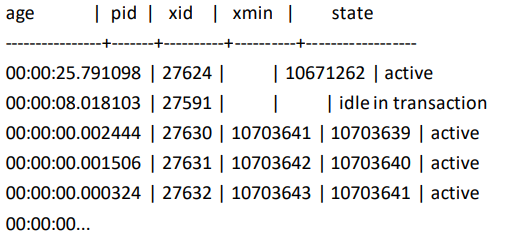
SELECT now() –
CASE
WHEN backend_xid IS NOT NULL
THEN xact_start
ELSE query_start END
AS age
, pid, backend_xid AS xid, backend_xmin AS xmin, stateFROM pg_stat_activity WHERE backend_type = ‘client backend’ ORDER BY 1
DESC;
sample output